Golang-optimization「2」: 字符串
前言
本系列的第二个部分,本文来谈谈程序员们喜闻乐见的string在Golang中有哪些值得注意的优化点
需要了解的词
string interning
一种在内存中仅存储每个唯一字符串的一个副本的技术unsafe.PointerGolang为“大胆的”程序员提供的更直接操作内存的方式,unsafe.Pointer是一种特殊意义的指针(通用指针),它可以包含任意类型的地址,有点类似于C语言里的void*指针,全能型的;在Golang中是用于各种指针相互转换的桥梁
选择合适的字符串拼接方式
首先来看看老生常谈的字符串拼接在 Golang 中的表现,这里我们主要看以下几个字符串拼接方法:fmt.Sprintf, +, strings.Join, bytes.Buffer, strings.Builder
实现一下单元测试:
1 | package test |
运行结果:
1 | $ go test -bench="Concat$" -benchmem . |
从基准测试的结果来看,使用 + 和 fmt.Sprintf 的效率是最低的,和其余的方式相比,性能相差约 1000 倍,而且消耗了超过 1000 倍的内存。当然 fmt.Sprintf 通常是用来格式化字符串的,一般不会用来拼接字符串。
strings.Builder、bytes.Buffer 和 []byte 的性能差距不大,而且消耗的内存也十分接近,性能最好且消耗内存最小的是 preByteConcat,这种方式预分配了内存,在字符串拼接的过程中,不需要进行字符串的拷贝,也不需要分配新的内存,因此性能最好,且内存消耗最小
可以看到 strings.Builder 的性能是最好的,当然在少量的字符串拼接上,还是可以直接使用+的
fmt.Sprintf, +, strings.Join这几个的性能都差不多,它们性能不佳的原因主要是每次+都要两个string复制到新分配的string中,拼接后的字符串越长,需要重新分配的内存越大,同样需要销毁的空间也越来越大
bytes.Buffer和 strings.Builder的原理类似,这是 Go 官方对 strings.Builder 的解释:
A Builder is used to efficiently build a string using Write methods. It minimizes memory copying.
同时string.Builder 也提供了预分配内存的方式 Grow:
1 | func builderConcat(n int, str string) string { |
使用了 Grow 优化后的版本的 benchmark 结果如下:
1 | BenchmarkBuilderConcat-8 16855 0.07 ns/op 0.1 MB/op 1 allocs/op |
与预分配内存的 []byte 相比,因为省去了 []byte 和字符串(string) 之间的转换,内存分配次数还减少了 1 次,内存消耗减半
比较 strings.Builder 和 +
strings.Builder 和 + 性能和内存消耗差距如此巨大,是因为两者的内存分配方式不一样。
字符串在 Go 语言中是不可变类型,占用内存大小是固定的,当使用 + 拼接 2 个字符串时,生成一个新的字符串,那么就需要开辟一段新的空间,新空间的大小是原来两个字符串的大小之和。拼接第三个字符串时,再开辟一段新空间,新空间大小是三个字符串大小之和,以此类推。假设一个字符串大小为 10 byte,拼接 1w 次,需要申请的内存大小为:
1 | 10 + 2 * 10 + 3 * 10 + ... + 10000 * 10 byte = 500 MB |
而 strings.Builder,bytes.Buffer,包括切片 []byte 的内存是以倍数申请的。例如,初始大小为 0,当第一次写入大小为 10 byte 的字符串时,则会申请大小为 16 byte 的内存(恰好大于 10 byte 的 2 的指数),第二次写入 10 byte 时,内存不够,则申请 32 byte 的内存,第三次写入内存足够,则不申请新的,以此类推。在实际过程中,超过一定大小,比如 2048 byte 后,申请策略上会有些许调整。我们可以通过打印 builder.Cap() 查看字符串拼接过程中,strings.Builder 的内存申请过程。
1 | func TestBuilderConcat(t *testing.T) { |
运行结果如下:
1 | ➜ test go test -run="TestBufferConcat" . -v |
bytes.Buffer无脑2n+1,strings.Builder前期为2n,到了512之后停止翻倍扩充
比较 strings.Builder 和 bytes.Buffer
strings.Builder 和 bytes.Buffer 底层都是 []byte 数组,但 strings.Builder 性能比 bytes.Buffer 略快约 10% 。一个比较重要的区别在于,bytes.Buffer 转化为字符串时重新申请了一块空间,存放生成的字符串变量,而 strings.Builder 直接将底层的 []byte 转换成了字符串类型返回了回来
- bytes.Buffer
1 | // To build strings more efficiently, see the strings.Builder type. |
- strings.Builder
1 | // String returns the accumulated string. |
bytes.Buffer 的注释中还特意提到了:
To build strings more efficiently, see the strings.Builder type.
阶段总结
- 字符串最高效的拼接方式是结合预分配内存方式
Grow使用string.Builder - 当使用
+拼接字符串时,生成新字符串,需要开辟新的空间 - 当使用
strings.Builder,bytes.Buffer或[]byte的内存是按倍数申请的,在原基础上不断增加 strings.Builder比bytes.Buffer性能更快,一个重要区别在于bytes.Buffer转化为字符串重新申请了一块空间存放生成的字符串变量;而strings.Builder直接将底层的[]byte转换成字符串类型返回
避免重复的字符串到字节切片的转换
在golang中,字符串的底层是字节slice,灵活地运用二者之间的类型转换可以避免很多的内存分配
byte切片转换成string的场景很多,有时候只是应用于在临时需要字符串的场景下,byte切片转换成string时并不会拷贝内存,而是直接返回一个string,这个string的指针(string.str)指向切片的内存地址
比如,编译器会识别如下临时场景:
使用
m[string(b)]来查找map(map中的key类型是string时,临时把切片b转成string)编译器为这种情况实现特定的优化:
1
2var m map[string]string
v, ok := m[string(bytes)]如上面这样写,编译器会避免将字节切片转换为字符串到 map 中查找,这是非常特定的细节,如果你像下面这样写,这个优化就会失效:
1
2key := string(bytes)
val, ok := m[key]字符串拼接,如<" + “string(b)” + ">
字符串比较: string(b) == “foo”
由于只是临时把byte切片转换成string,也就避免了因byte切片内容修改而导致string数据变化的问题,所以此时可以不必拷贝内存
但反过来并不是这样的,string转成byte切片需要一次内存拷贝的动作,其过程如下:
- 申请切片内存空间
- 将
string拷贝到切片中
所以不要反复从固定字符串创建字节slice,因为重复的切片初始化会带来性能损耗;尽可能的执行一次转换并捕获结果,以下是相关的Benchmark
1 | // BenchmarkBad |
字符串和字节切片的更高效互转
在面对原地转换的场景时,利用 string 和 byte slice 底层数据结构实现的技巧(需要比较aggressive的使用到unsafe.Pointer),如果需要大量互转可以考虑使用这种方式:
1 | /* |
str2bytes中,直接复用string中的Data和Len,再将Cap设为与Len相同,即可直接强转成*[]byte
反之亦然,在bytes2str中,直接复用byte slice中的 Data和Len,即可强转为*string
在合适的时机使用字符串池(string interning)
string interning是一种在内存中仅存储每个唯一字符串的一个副本的技术,基于它我们可以显著地优化使用大量重复字符串应用的内存使用量
而在golang中,string类型的数据结构为:
1 | type stringStruct struct { |
结构很简单:
- str: 字符串的首地址
- len: 字符串的长度
字符串生成时,会先构建stringStruct对象,再转成string;转换的源码如下:
1 | // go:nosplit |
并且在golang中,字符串是不可变的(不管是否显式使用const声明),我们可以通过以下试验看到:多个字符串可以共享底层数据
1 | package main |
大多数语言(包括golang)都支持对编译期字符串常量的string interning:
1 | s1 := "12" |
但对于运行时的字符串变量并不支持(或者说没有进行string interning):
1 | s1 := "12" |
实现 string interning
要实现string interning很简单,我们只需要设计一个字符串池的数据结构,实现其Get和Set方法即可
简单的实现string interning(thread unsafe):
1 | type stringInterner map[string]string |
以上的 stringInterner 在将 []byte 转换为 string 的同时,检查此 string 是否已经被 interned,如果是则直接返回老的 string,否则 intern 新的 string
减少重复内存分配
由于 string(b) 的原理是直接将 b 作为 string 的 Data,如果程序不断读入新的字节流,会不断生成新的 string 对象,string 占用的空间呈线性增长。上面这段函数,只使用 []byte 作为比较的依据,新生成的 string(b) (分配在栈上)会随着函数结束而被回收,只有未命中的 string 会被缓存在堆上
减少比较字符串开销
除了降低内存的重复分配外,string interning还可以在稳定的时间内比较被占用的字符串是否相等;编译器只需要检查两个指针是否相等(转到源代码),而不是检查字符:
1 | TEXT cmpbody<>(SB),NOSPLIT,$0-0 |
以下是使用和不使用string interning情况下的字符串比较Benchmark:
1 | func benchmarkStringCompare(b *testing.B, count int) { |
使用string interning字符串的比较速度保持恒定,不受字符数量的影响:
1 | BenchmarkStringCompare1-4 500000000 2.93 ns/op |
线程安全和淘汰策略
上面的简单实现是基于golang原生map的,很明显是非线程安全的;如果真的有multi goroutine使用string intern的场景的话,可以参考使用github.com/josharian/intern
它的工作原理是暴力的直接使用sync.Pool,因为sync.Pool访问是并发安全的,并且它在很大程度上解决了淘汰策略的问题,因为sync.Pool中的内容通常最终会被GC(有关淘汰策略,可以参考Go issue 29696)
阶段总结
string interning可以以CPU时间为代价来节省内存——字符串池中的每次查找都需要对输入字符串进行哈希散列(这可能不适用于CPU资源吃紧的应用)
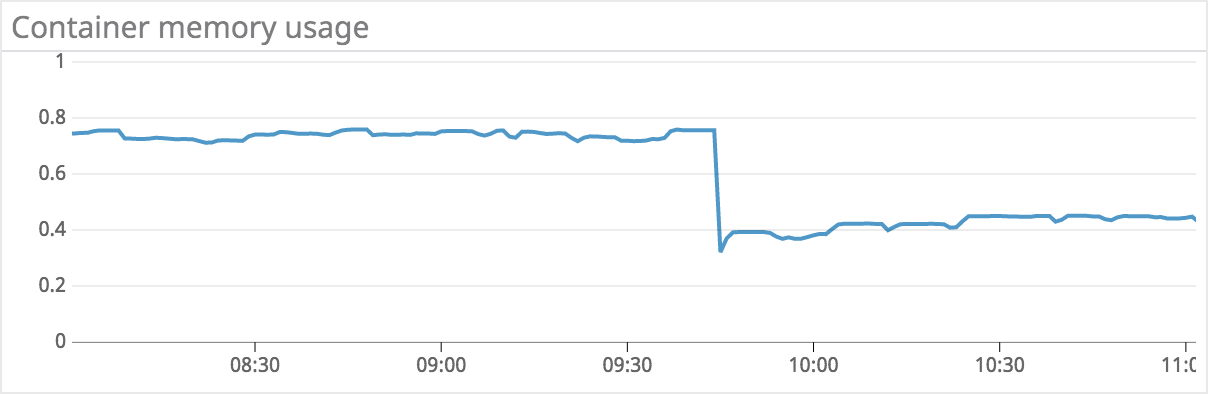
在合适的场景使用string interning能显著的减少内存资源使用,以下资源监控图来自真实的string interning优化案例:
总结
总结下来,对Golang的字符串我们需要注意以下几点:
- 牢记
string和[]byte的底层数据结构 - 在字符串拼接时注意使用效率(根本的性能差异也是由拼接时的内存分配方式导致的)
- 在合适的场景利用好字符串池,可以收获惊人的内存优化