

焦虑,忙碌以及颠覆工作内容的一年——2025年终总结
前言 还是一样的对26年的到来没有实际感受,25年是我的本命年,硬要说有什么劫难,那就是我的工作内容本身了,总之一切都还顺利,或许写完这篇年终总结,我就会对过去的一年有一些体会了吧。 回望 工作 关于「剑」:那一次真正“主动出击” 如果要用一件事来概括我今年的‘剑’,我会选择年初时面对各方面都不清晰的AI工作台项目时,选择直接带领Fibona全团队搬到前海数码大厦来投入冲刺的那一次决策。 作为项目亲历者和牵头人之一,我认为当时的情况是:产品形态不清晰,涉及3方以上的合作,合作模式/边界不明确,以及最重要的,大家都有自己的想法,没有能够“一言堂”说清楚直接推进项目的人。讲实话,从我的角度,在经过了最初一周的沟通后,我心里打了一万个退堂鼓;但我想真正让我下定决心出剑的,是我那一份想带团队做好做完整一件事情的心气和主观意愿,最终它还是推着我逆着惰性和环境,做出了决策,带领Fibona全团队搬过来数码大厦准备战斗。 这次主动出击后,我们在一个月的时间内,多线推进,一方面在技术侧快速迭代构建demo能力和内部运营端能力,输送沟通对齐所需弹药,另一方面尝试明确初版产品形态及合作模式/边界, ...

成长于焦虑与挣扎中——2023年终总结
前言 逼近的2024始终没有给我实质的“新年到来”的感觉,直到我又一次在元旦这一天的晚上看到了回春丹的演出 我才终于意识到 —— 2023真的过去了 回望 工作 2023年,我继续在腾讯工作,职业发展上完成了基本的目标,项目也有了一些进展。然而,自22年底开始,曾经被大家鄙视为“智障”的大语言模型卷土重来,伴随着庞大的大语言模型相关信息流和随着大环境恶化而来的裁员潮,我开始感到了一丝迷茫和焦虑。 我曾经认为自己对后台开发,软件架构等方面有着不少的了解,也沉淀了不少宝贵的知识和经验;自认为是一个技术上的“多面手”,但随着大语言模型的出现,我发现我在各个领域的浅薄了解完全被冲淡了,不禁感叹自己还有太多需要学习的地方。大语言模型的复杂性和强大功能让我感到既兴奋又畏惧。我开始担心自己会被时代淘汰,无法跟上技术发展的步伐。 我开始花费几乎所有闲暇时间,甚至一小部分的工作时间来研究大语言模型,阅读论文、试用日新月异的LLM应用,也不断的在与其它同事做一些相关交流。我试图了解这些模型的工作原理,并探索它们的潜在应用。然而,我发现自己越深入地研究,就越感到自己的渺小(甚至开始感叹自己为什么以前 ...
LLM远不仅仅是Chat Model——LangChain基本概念与使用示例
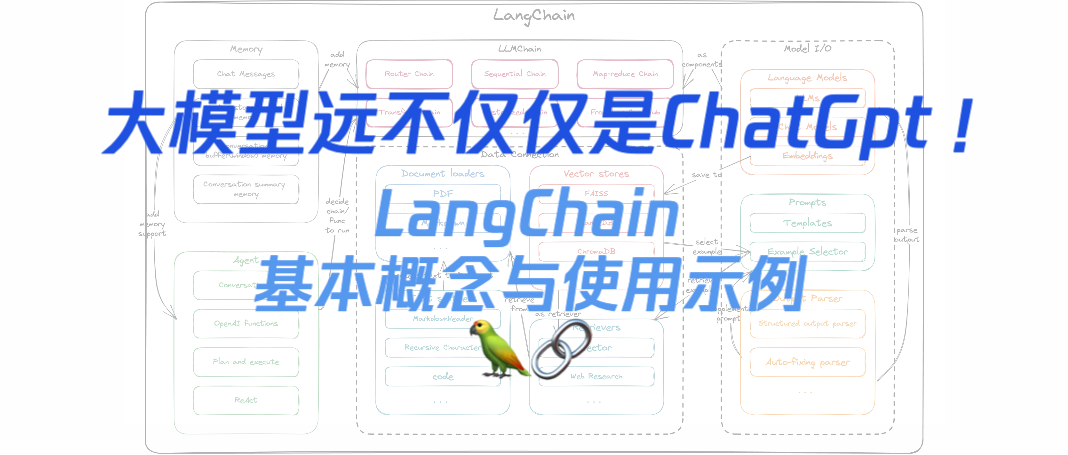
前言 一图胜千言,LangChain已经成为当前LLM应用框架的事实标准,这篇文章就来对LangChain基本概念以及其具体使用场景做一个整理 LangChain是什么 LangChain是一个基于大语言模型的应用开发框架,它主要通过两种方式规范和简化了使用LLM的方式: 集成:集成外部数据(如文件、其他应用、API数据等)到LLM中 Agent:允许LLM通过决策与特定的环境交互,并由LLM协助决定下一步的操作 LangChain的优点包括: 高度抽象的组件:规范和简化与语言模型交互所需的各种抽象和组件 高度可自定义的Chains:提供了大量预置Chains的同时,支持自行继承BaseChain并实现相关逻辑以及各个阶段的callback handler等 活跃的社区与生态:Langchain团队迭代速度非常快,能快速使用最新的语言模型特性,该团队也有langsmith, auto-evaluator等其它优秀项目,并且开源社区也有相当多的支持 LangChain的主要组件 这是一张LangChain的组件与架构图(langchain python和langchain ...

如何为私有大语言模型快速沉淀高质量数据集
前言 在构建text-to-sql模型时,高质量的数据和有效的数据流程是必不可少的。目前市面上已经有许多优秀的开源大模型,如ChatLLaMa、Alpaca、Vicuna、以及Databricks-Dolly,Stable Diffution母公司发布的StableLM等 此外,还有一些训练框架可供选择,比如LMFlow和微软最近开源的DeepSpeed等 但即使开源的大模型和训练框架都越来越多,它们也都离不开高质量数据和生产高质量数据的流程,这也是一切模型构建的前提;这篇文章就来讲一下在私有项目中我是如何持续积累高质量数据集,并沉淀相关流程框架的 需要了解的词 Prompt Engineering 一种为生成式AI模型设计和提炼prompt的方法论 / 框架,通常是规定 / 限制从模型中获得所需输出的框架,并持续的通过实验和分析来优化这些prompt Prompt Engineering很重要,因为它可以显著影响NLP模型的性能,特别是对于微调任务。设计良好的prompt可以使模型生成更准确和相关的响应,而设计不当的提示可能会导致不准确或无用的输出,Prompt Engine ...

Redis性能之巅:延迟问题排障指南
前言 在 Redis 的实际使用过程中,我们经常会面对以下的场景: 在 Redis 上执行同样的命令,为什么有时响应很快,有时却很慢 为什么 Redis 执行 GET、SET、DEL 命令耗时也很久 为什么我的 Redis 突然慢了一波,之后又恢复正常了 为什么我的 Redis 稳定运行了很久,突然从某个时间点开始变慢了 这时我们还是需要一个全面的排障流程,不能无厘头地进行优化;全面的排障流程可以帮助我们找到真正的根因和性能瓶颈,以及实施正确高效的优化方案 这篇文章我们就从可能导致 Redis 延迟的方方面面开始,逐步深入排障深水区,以提供一个「全面」的 Redis 延迟问题排查思路 需要了解的词 Copy On Write COW 是一种建立在虚拟内存重映射技术之上的技术,因此它需要 MMU 的硬件支持,MMU 会记录当前哪些内存页被标记成只读,当有进程尝试往这些内存页中写数据的时候,MMU 就会抛一个异常给操作系统内核,内核处理该异常时为该进程分配一份物理内存并复制数据到此内存地址,重新向 MMU 发出执行该进程的写操作 内存碎片 操作系统负责为每个进程分配物理内 ...

clash-on-linux配置
前言 本文记录一下 clash on linux 的配置流程 安装 Clash 下载当前操作系统与 CPU 架构对应的包文件 💡 首先查看当前系统版本 以下几种方法都可以查看系统版本(部分云厂商服务器会改动一些版本名): 1234uname -agrep 'VERSION=' /etc/os-releaselsb_release -a | grep Descriptionhostnamectl | grep Ubuntu 容器内需要使用以下命令查看容器系统版本: 1cat /etc/issue 我的服务器当前的系统版本为Ubuntu 20.04.5 LTS,所以直接下载linux-amd64版本即可,我下载的版本为clash-linu 1.13.0 ,最新的版本可以去github release查看 1wget -O clash.gz https://github.com/Dreamacro/clash/releases/download/v1.13.0/clash-linux-amd64-v1.13.0.gz 下载好后解压安装包中 c ...
![\[vscode issue\] Golang Debug 无法命中断点](https://kevinello-1302687393.file.myqcloud.com/picgo/2023/02/28/202302281702991-ae1947.png)
\[vscode issue\] Golang Debug 无法命中断点
VSCode Golang Debug无法命中断点问题修复 发现在VSCode中连接公司DevBox调试Golang程序时,无法命中断点 在launch.json中添加参数 这样Debug程序会输出日志并停在程序入口,观察日志发现 有setBreakPoints的输入,也就是说编辑器(VSCode)是正确识别到了断点并传递给dlv-dap dlv报错:找不到文件 在dlv控制台执行 dlv sources,获取dlv装载的文件,发现有目标文件,但目录并非/home而是/data00/home 观察VSCode的控制台打印的cwd,发现vscode识别的路径为/home stat /home,发现其为软链接,目标目录为/data00/home 定位原因,dlv将软链接文件装载为指向的物理文件,vscode传入的是软链接路径,二者路径不一致,dlv装载的内容不包含软链接路径 解决方法 在launch.json中添加"substitutePath": [{"from": "/home ...
从Redis事务到Redis pipeline
前言 Redis是非常经典优秀的内存数据库,其拥有非常高的性能;其单机实例在数据结构设计良好,实例健康的情况下能达到10w左右的OPS 现代应用程序对实时性的需求和计算机体系结构的限制决定了:很多时候我们都需要将in-memory data stores放在现代应用程序的中心,因此在很多常见场景中我们也都能见到 Redis,如: 数据库:可作为传统的基于磁盘的数据库的替代方案。Redis非常简单粗暴地以持久性换取运行速度,并且支持异步磁盘持久化;同时提供了一组丰富的数据原语和非常广泛的命令列表 消息队列:Redis 的 blocking list 和低延迟特性使其成为Message Broker服务的良好支持 内存缓存:Redis 提供了可配置的针对过期 key 的驱逐策略,包括但不限于 LRU 和 LFU等等(下面会提到),使得 Redis 成为了缓存服务器的理想选择,并且 Redis 还支持持久化到磁盘以及快速恢复的机制,提高了其可靠性 即使作为一款高性能数据库的,我们也必须建设良好的监控,保障Redis的稳定性和可靠性;本文就从来探讨一下 Redis 有哪些值得注意的指标 ...
\[vscode issue\] Cannot read properties of undefined (reading 'addr')
现象 在一些init函数中打下断点,执行时达到断点后,Debug Console 输出一下信息后会直接结束,无法继续进行调试 12345Unhandled error in debug adapter: TypeError: Cannot read properties of undefined (reading 'addr') at GoDebugSession.convertDebugVariableToProtocolVariable (/root/.vscode-server/extensions/golang.go-0.37.1/dist/debugAdapter.js:16728:25) at /root/.vscode-server/extensions/golang.go-0.37.1/dist/debugAdapter.js:16249:55 at processTicksAndRejections (node:internal/process/task_queues:96:5) at async Promise.all ...
Linux零拷贝实现与实际应用
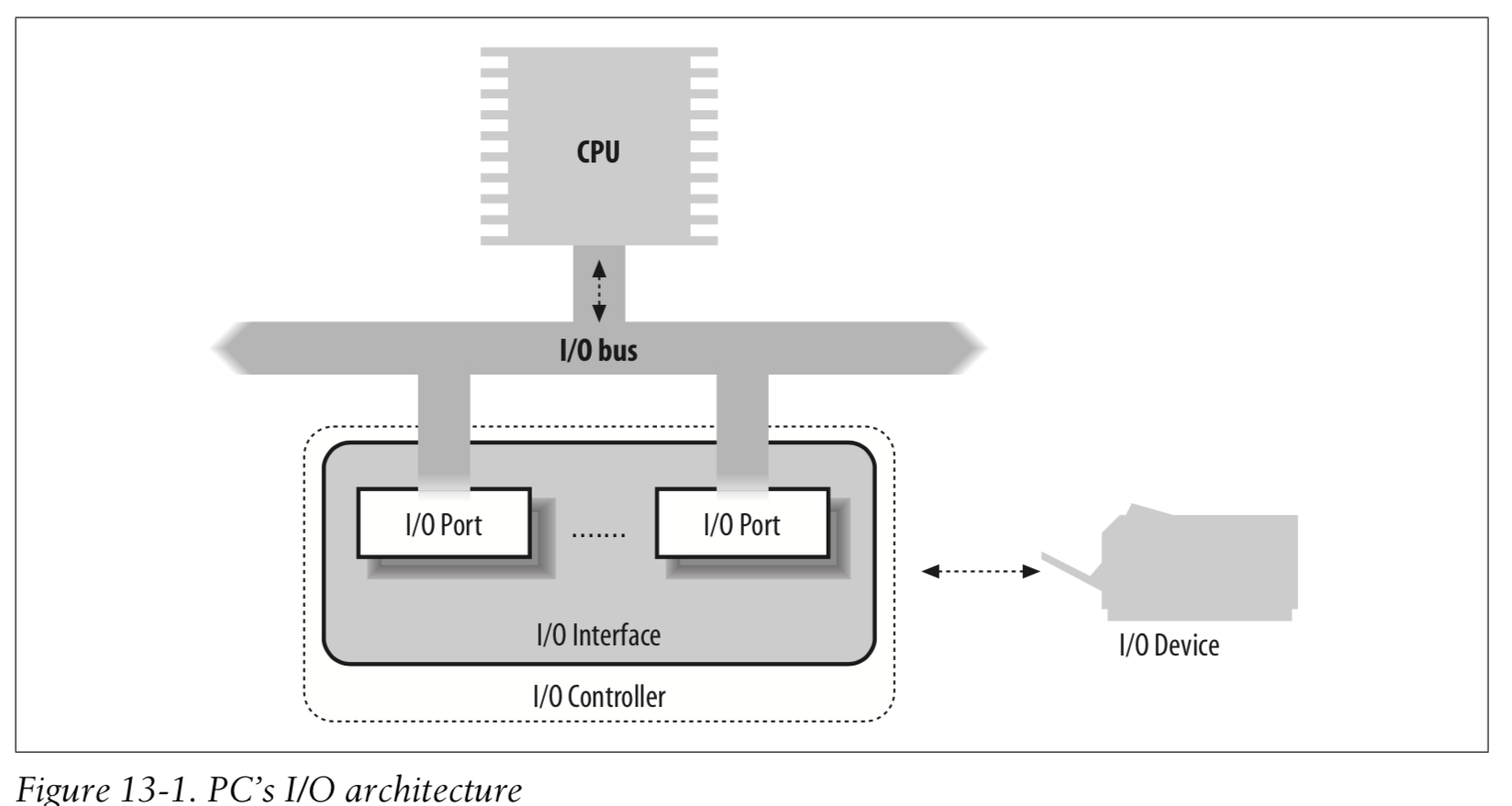
前言 存储器是计算机的核心部件之一,在完全理想的状态下,存储器应该要同时具备以下三种特性: 速度足够快:存储器的存取速度应当快于 CPU 执行一条指令,这样 CPU 的效率才不会受限于存储器 容量足够大:容量能够存储计算机所需的全部数据 价格足够便宜:价格低廉,所有类型的计算机都能配备 但是现实往往是残酷的,我们目前的计算机技术无法同时满足上述的三个条件,于是现代计算机的存储器设计采用了一种分层次的结构: 从顶至底,现代计算机里的存储器类型分别有:寄存器、高速缓存、主存和磁盘,这些存储器的速度逐级递减而容量逐级递增 存取速度最快的是寄存器,因为寄存器的制作材料和 CPU 是相同的,所以速度和 CPU 一样快,CPU 访问寄存器是没有时延的,然而因为价格昂贵,因此容量也极小,一般 32 位的 CPU 配备的寄存器容量是 32✖️32 Bit,64 位的 CPU 则是 64✖️64 Bit,不管是 32 位还是 64 位,寄存器容量都小于 1 KB,且寄存器也必须通过软件自行管理 第二层是高速缓存,也即我们平时了解的 CPU 高速缓存 L1、L2、L3,一般 L1 是每个 CPU ...