从Redis事务到Redis pipeline
前言
相信对关系性数据库有使用经验的,都对事务操作很熟悉,为了确保连续多个操作的原子性,我们常用的数据库都会有事务的支持,Redis 也不例外;但它又和关系型数据库支持的事务不太一样
需要了解的几个词
- 事务:数据库事务通常包含了一个序列的对数据库的读/写操作。包含有以下两个目的:
- ACID:关系性数据库事务具有的四个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
- 悲观锁(Pessimistic Lock):顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会 block 直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁
- 乐观锁(Optimistic Lock):顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。乐观锁策略:提交版本必须大于记录当前版本才能执行更新
Redis事务
基本使用形式
- MULTI(开启事务)
- 一系列命令加入队列
- EXEC(执行事务)/ DISCARD(取消事务)
Redis 事务可以一次执行多个命令,本质是一组命令的集合;一个事务中的所有命令都会序列化,按顺序地串行化执行而不会被其它命令插入,不许加塞
可以保证一个队列中,一次性、顺序性、排他性的执行一系列命令(Redis 事务的主要作用其实就是串联多个命令防止别的命令插队)
| 命令 | 描述 |
|---|---|
| MULTI | 将客户端的 REDIS_MULTI 选项打开, 让客户端从非事务状态切换到事务状态 |
| EXEC | 执行所有事务块内的命令 |
| DISCARD | 取消事务,放弃执行事务块内的所有命令 |
| WATCH | 监视一个(或多个)key,如果在事务执行之前这个(或多个)key被其他命令所改动,那么事务将被打断 |
| UNWATCH | 取消 WATCH 命令对所有 keys 的监视 |
执行一帆风顺,到这里一片祥和:
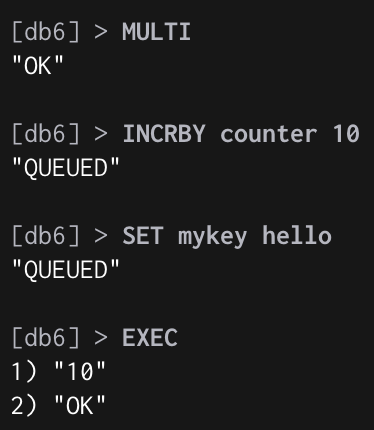
但在实际的生产环境中往往还会遇到一些问题:
- 事务在执行
EXEC之前,入队的命令可能会出错。比如说,命令可能会产生语法错误(参数数量错误,参数名错误等等,往往是因为调用者没有对参数进行判空处理) - 命令可能在
EXEC调用之后失败。举个例子,事务中的命令可能处理了错误类型的键,比如将列表命令用在了字符串键上面 - OOM 导致 redis server 被kill
Redis 针对如上两种错误采用了不同的处理策略,对于发生在 EXEC 执行之前的错误,服务器会对命令入队失败的情况进行记录,并在客户端调用 EXEC 命令时,拒绝执行并自动放弃这个事务(Redis 2.6.5 之前的做法是检查命令入队所得的返回值:如果命令入队时返回 QUEUED ,那么入队成功;否则,就是入队失败)
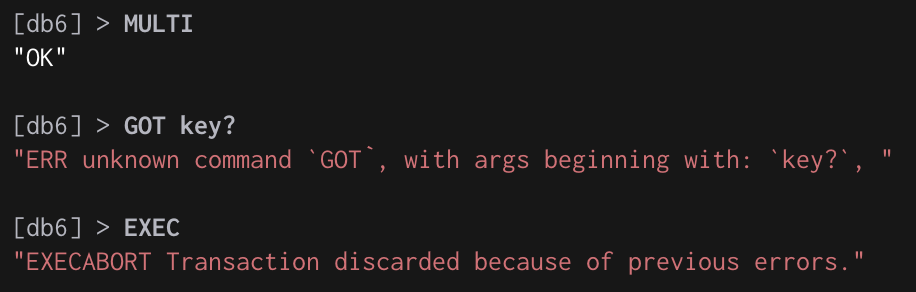
如上图,EXEC前命令入队时出现了语法错误,EXEC时则会直接拒绝该事务
对于那些在 EXEC 命令执行之后所产生的错误, 并没有对它们进行特别处理: 即使事务中有某个/某些命令在执行时产生了错误, 事务中的其他命令仍然会继续执行
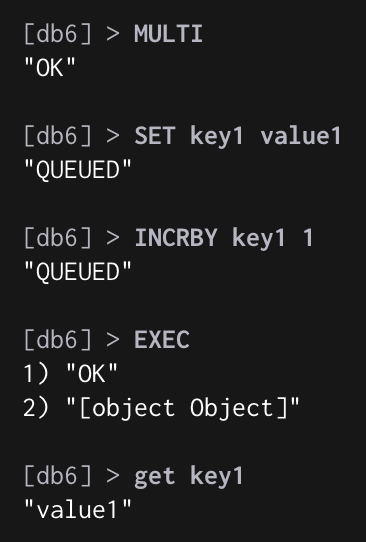
如上图,INCRBY key1 1语法没有错误,但key1的value是字符串类型,不能对其使用INCRBY;这种情况执行EXEC不会报错,只有那一条命令执行失败
也就是说Redis是不支持回滚的
为什么 Redis 不支持回滚
This is the moment where one might say that rollbacks would be nice to have. I might agree if not for two considerations:
- The snapshotting mechanism required to implement rollbacks would have a considerable computational cost. That extra complexity wouldn’t sit well with Redis’ philosophy and ecosystem.
- Rollbacks can’t catch all errors. In the example above, we set “counter” to “banana” in order to show a blatant error, but in the real world the process that used the “counter” key in the wrong way might instead have deleted it, or put in a credit-card number, for example. Rollbacks would add a considerable amount of complexity and would still not fully solve the problem.
The second point is particularly important because it also applies to SQL: SQL DBMSs offer many mechanisms to help protect data integrity, but even they can’t completely protect you from programming errors. On both platforms, the burden of writing correct transactions remains on you.
翻译一下,两句话:
回滚是非常复杂的操作,不符合Redis的设计哲学和生态系统,且回滚也不能解决所有问题需要回滚完全是你们的编程错误导致的,这些错误应该在开发时就被发现,我Redis不背这锅;鉴于没有任何机制能避免程序员自己造成的错误, 并且这类错误通常不会在生产环境中出现, 所以 Redis 选择了更简单、更快速的无回滚方式来处理事务
其实这篇解释很有意思,其中也多次提到了Redis的设计哲学以及与SQL的对比,感兴趣的同学可以详细阅读(看别人撕逼真有趣)
基于WATCH的事务
how do you create a transaction that depends on the data present in Redis? For this purpose, Redis implements WATCH, a command for performing optimistic locking.
如何创建一个依赖于Redis中已存在的数据的事务? 为此,Redis实现了WATCH,这是用于执行乐观锁的命令
Redis实现的乐观锁
WATCH 命令用于在事务开始之前监视任意数量的键: 当调用 EXEC 命令执行事务时, 如果任意一个被监视的键已经被其他客户端修改了, 那么整个事务将被打断,不再执行, 直接返回失败
WATCH命令可以被调用多次; 对键的监视从 WATCH 执行之后开始生效, 直到调用 EXEC为止
当多个Redis客户端尝试使用事务改动同一个被WATCH监视的键时,Redis会自动抛弃某些事务,这时客户端需要重试该事务
WATCH的实现是基于redis中保存的watched_keys 字典实现的,字典的键是这个数据库被监视的键, 而字典的值则是一个链表, 链表中保存了所有监视这个键的客户端
具体实现见官方文档
Pipeline
Another way to reduce the latency of Redis queries is by using pipelining. When you pipeline a group of operations, they are sent in a single batch that, while bigger and slower to process, requires only a single request-response round trip. This consolidation of trips makes for substantial overall latency reductions.
Redis事务在发送每个指令到事务缓存队列时都要经过一次网络读写,当一个事务内部的指令较多时,需要的网络 IO 时间也会线性增长。所以通常 Redis的客户端在执行事务时都会结合 pipeline一起使用,这样可以将多次 IO 操作压缩为单次 IO 操作
这里基于go-redis客户端实现的pipeline聊一下pipeline的使用
1 | // TxPipeline acts like Pipeline, but wraps queued commands with MULTI/EXEC. |
上面是go-redis中实现的事务pipeline,与普通pipeline不同的地方仅在于它的Exec方法,txPipelineProcessCmds中调用了txPipelineWriteMulti:
1 | func txPipelineWriteMulti(cn *pool.Conn, cmds []Cmder) error { |
可以看到TxPipeline只是做了一下包装使其支持事务
pipeline的进阶使用
pipeline的基本使用非常简单,但有几点要注意:
Note, however, that a pipeline operation could block your application if it is waiting for replies without sending the pipeline – Redis will provide all of the replies to the pipelined stream of commands only after the pipeline has been sent. Also bear in mind that when using pipelining, Redis caches all the responses in memory before returning them to the client in bulk, so pipelining thousands of queries (especially those that return a large amount of data) can be taxing to both the server and client. If that is the case, use smaller pipeline sizes.
- 一个
pipeline包含的命令不应太多,因为在使用流水线操作时,Redis在将所有响应批量返回给客户端之前会将所有响应缓存在内存中,因此对数千个查询(特别是那些返回大量数据的查询)进行流水线操作可能会对服务器和客户端都造成负担 - 因为即使是
TxPipeline也只是弱事务性的,我们应该在设计业务模型时尽可能保证数据安全性,降低事务出错带来的影响(不要把自己带入基于SQL的设计思维)
对于第一个问题我们可以简单封装一下TxPipeline:
1 | var MaxPipeLineCmdCount = 100 |
当然也可以采用定时任务的方式检查cmd个数提交pipeline
TxPipeline与Lua脚本的选择
官方解释:
There are, in my opinion, a couple of reasonable situations where you might legitimately prefer transactions with optimistic locking over Lua:
- The keys your transaction depends on are not modified frequently, meaning that you are confident optimistic locking will almost never abort transactions.
- You depend on a lot of logic written on the client side—or maybe a third-party service—so there is no easy way to move that logic to a Lua script.
Unless both these points are true for your application, I recommend you choose Lua over WATCH
值得注意的是官方对比的是带WATCH的事务与Lua脚本
翻译一下
只有两种场景下应该使用带WATCH的事务而不是Lua脚本:
- 事务依赖的数据并不会被频繁更改,也就是说我们有信心
WATCH锁基本不会被打破 - 客户端的业务逻辑比较复杂,将其写成
Lua脚本的成本较大
总结
Redis事务仅具有一致性与隔离性,不保证原子性和持久性,所以在设计使用Redis的业务时需要保证数据安全性,在pipeline与Lua脚本的取舍上其实也不用太过纠结,简单的业务可以直接封装成Lua脚本
在使用pipeline时需要注意监控其命令个数,避免对服务器和客户端造成过大的负担,导致业务延迟乃至于OOM