Distributed Tracing in Grafana -- Jaeger & Tempo
前言
在近几个月对某产品后台微服务的SLI建设过程中,逐渐意识到这类监控的最佳方式还是通过jaeger/opentracing这类链式tracing才能以最佳的监控数据结构提供全链路的数据监控
并且最近也看到了Tempo — 来自Grafana Lab的tracing backend,可以更好的处理大数据量的tracing以及更好地兼容在Grafana上的展示
于是写一篇文章来小小整理一下Jaeger和Tempo的内容
需要了解的词
tracing
追踪数据流的工具,下面会详细介绍
Grafana
基于
Golang实现的完整可视化面板平台,同时也提供告警等功能OpenTracing
由
Tracing通用API规范、框架和库组成,可以在任何应用程序中支持Distributed Tracing
Tracing是什么
尽管我们十分熟悉我们编写的系统,但在线上环境中,它对于我们来说依旧是黑盒;可能你会说我们有丰富的日志,但当系统日渐庞大,业务逻辑逐渐繁杂之后,再丰富的日志对于我们的运维排查来说也是杯水车薪,并且日志采集,日志埋点,和日志存储都带来不小的成本,复杂的日志反而会拖后腿,加大我们的排查难度
在这种场景下,tracing的优越性就完全体现出来了
与离散的日志不同,tracing提供了更广泛和连续的应用程序视图。tracing能帮助我们了解进程/事务/实体的流程(大多数情况下是数据流),同时遍历应用程序堆栈并找出各个阶段的性能瓶颈,便于我们进行性能优化
而Distributed Tracing则是tracing在微服务架构中实现的形式,因为传入请求(数据)会跨越多个微服务,并且每个微服务可以在该请求上进行各种结构的操作,导致复杂性增加,并且我们在排除问题时需要更多时间去定位问题所在的微服务
Distributed Tracing可以让我们深入了解每一个操作单元,并查明性能瓶颈或深入埋藏的bug
Trace基本原理
基本元素
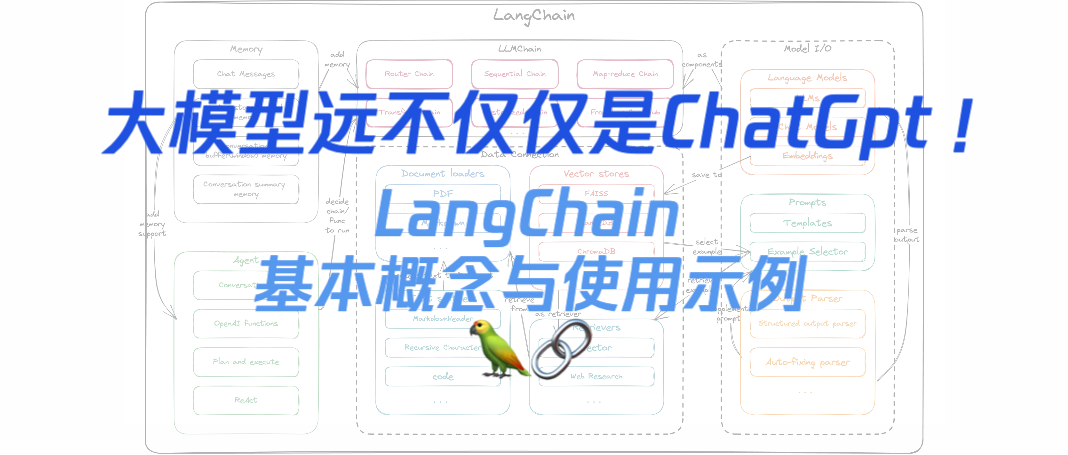
Span
Distributed Tracing的基本单位,包括名称、开始时间和持续时间,用户的请求 / 事务将以span为单位拆解成很多子步骤(由单个微服务完成的单个工作)Trace
Distributed Tracing的另一个最重要的基本元素,遍历整个微服务系统的链式结构记录(随请求信息在微服务之间传输),用于可视化请求 / 事务,我们可以看到用户请求如何跨服务执行,并发现需要被关注的内容,而无需手动地在多个仪表板之间切换(这就是链式请求的优越性)Tags
标识Span的
key-value信息,可以帮助我们查询,过滤和分析trace信息Logs
同样也是
key-value形式的归属于Span的由微服务输出的日志信息Span-context
归属于Span的上下文,包含
key-value形式的信息,canceler方法等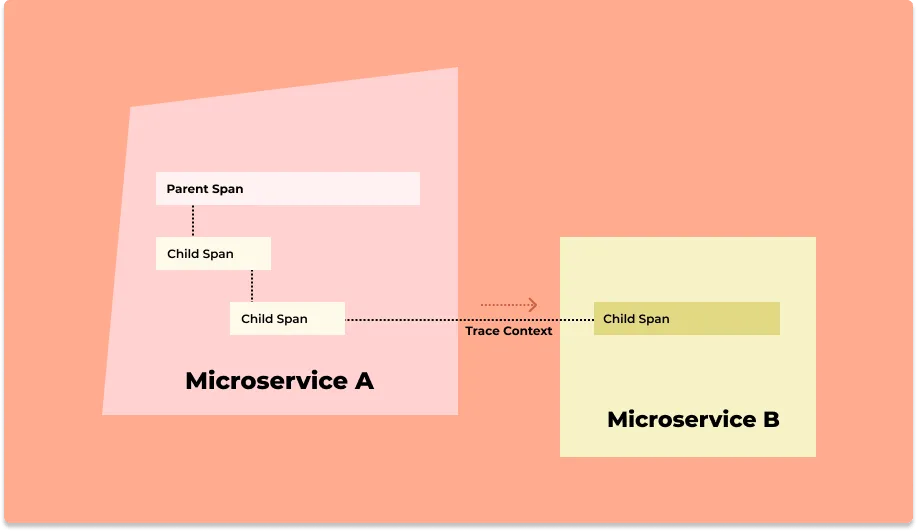
Jaeger基本架构
Jaeger支持两种流行的开源NoSQL数据库作为跟踪存储后端:
- Cassandra
- ElasticSearch
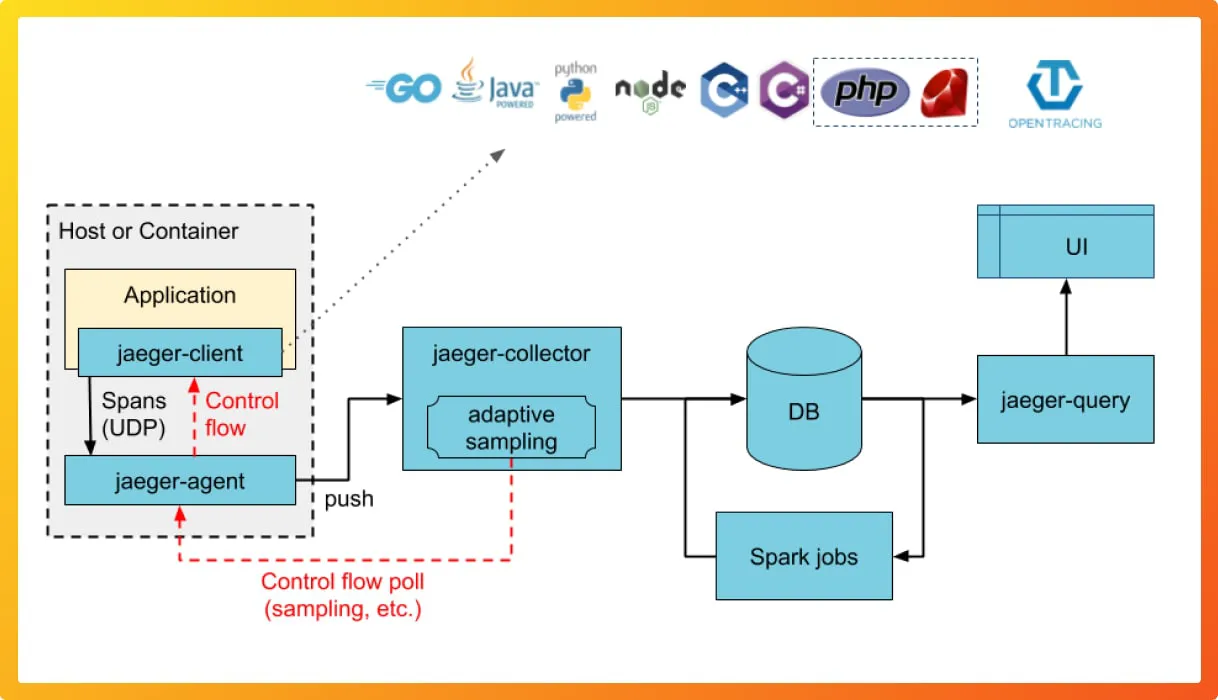
Tempo基本架构
Tempo和Jaeger的架构基本一致,唯一的不同体现在数据存储上
Tempo不需要像Cassandra和ElasticSearch这样的数据库,它的架构中有以下组件:
- Distributor
用于兼容多种格式的Span - Ingestor
将trace分块打包传输给server,类似pipeline,节省网络IO - Query frontend
Tempo使用Grafana作为前端 - Querier
负责从后端存储查找请求对应的跟踪ID - Compactor
清理存储中的记录,减小存储压力
比较Jaeger和Tempo
对于一个Distributed Tracing系统来说,它的以下四个组件是需要我们注意的:
- 插桩
- Pipeline
- 存储
- 可视化
插桩
Jaeger的插桩客户端库基于OpenTracing api,支持大部分语言:
- Golang
- Java
- Node.js
- Python
- C++
- C#
而Grafana Tempo支持多种插桩标准,这让应用程序开发者有了更自由的选择;下面是Grafana Tempo支持的用于客户端插桩的流行框架列表:
- OpenTracing/Jaeger
- Zipkin
- OpenTelemetry
Pipeline
当数据量越来越大时,很明显我们不能还是将tracing数据一条一条的发送到服务端进行存储;这时候就需要一个tracing pipeline来缓存数据,进行预聚合后再发送到服务端
Jaeger在这方面提供了Jaeger Collector,如上文中的Jaeger架构图中所示;收集器在存储跟踪数据之前验证tracing、对tracing进行索引并进行了预聚合,自适应抽样等工作
Grafana Tempo有Grafana agent,部署在应用程序附近;它可以快速从应用程序中收集tracing,并进行tracing预聚合和后端路由等工作
存储
Jaeger配备了简单的内存存储用于测试设置,并支持两种流行的开源NoSQL数据库作为tracing存储后端(上文中有提到),在查询性能上会受限
Grafana Tempo有自己的定制TempoDB来存储tracing数据,TempoDB支持S3、GCS、Azure、本地文件系统,还可以选择使用Memcached或Redis来提高查询性能
可视化
在可视化层方面,Grafana Tempo更有优势(毕竟依托于Grafana,这就是它最大的优势),Grafana Tempo是一个开源数据可视化层的分布式跟踪工具,我们可以将不同的数据源连接到Grafana以实现可视化,并且Grafana就有一个内置的Tempo数据源,可以用来查询Tempo和可视化tracing。
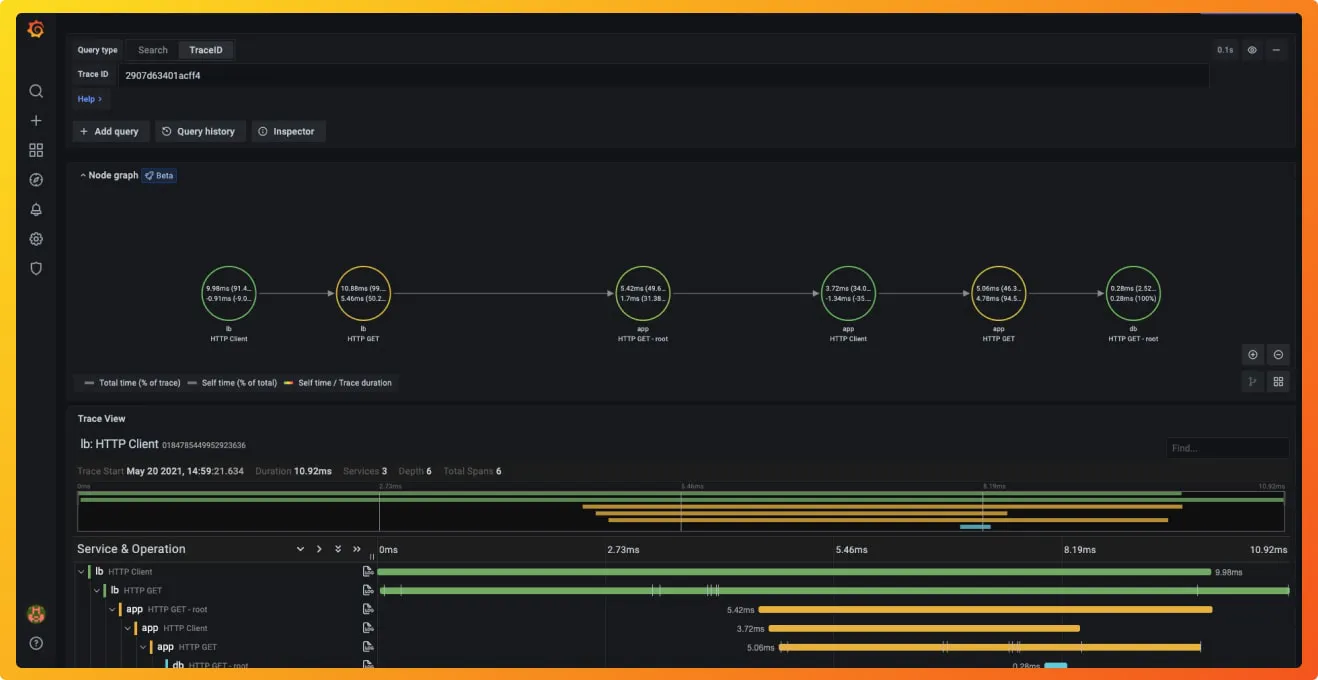
Jaeger的UI也很基本很全面,但没有丰富的图表和百分位统计等功能,查询的功能也很局限
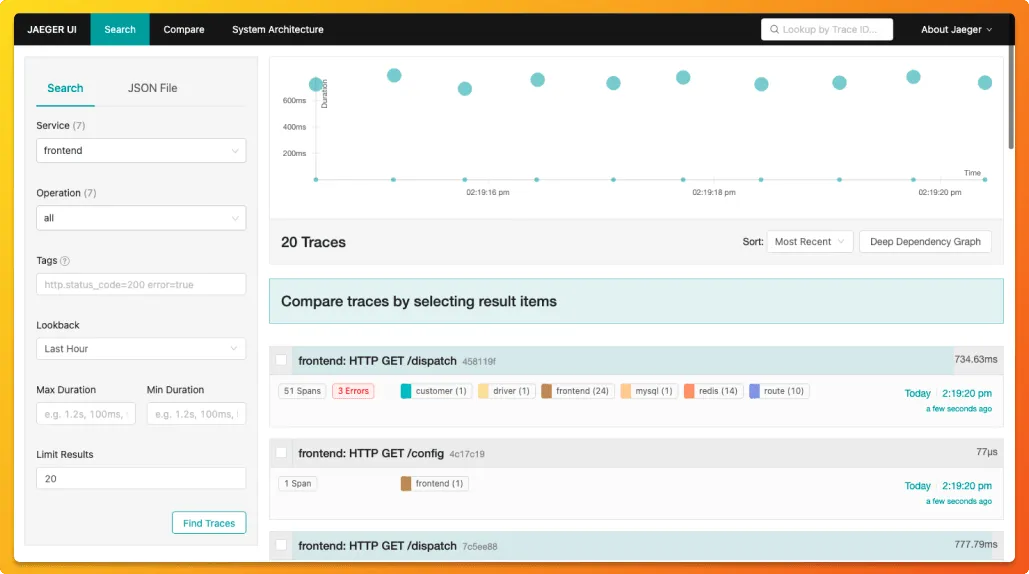
总结
Grafana Tempo和Jaeger的最大区别就体现在存储和可视化上了;在可视化上依托于Grafana本身的Grafana Tempo无疑是很ok的,但在查询性能上二者虽然存储介质不同,查询性能也都没有质的差距