Golang-optimization「1」: 数组和切片
前言
本系列的第一个部分,本文就来谈谈日常开发中几乎是最常用的,且在 Golang 中又有一定特殊性的数组和切片中有哪些值得注意的优化点
数组和切片的具体实现
首先我们来谈一谈数组和切片的具体实现
Go 的切片(slice)是在数组(array)之上的抽象数据类型,数组类型定义了长度和元素类型,数组变量属于值类型(value type),因此当一个数组变量被赋值或者传递时,实际上会复制整个数组
由于数组固定长度,缺少灵活性,我们在大部分场景下会选择使用基于数组构建的功能更强大,使用更便利的切片类型
切片使用字面量初始化时和数组很像,但是不需要指定长度:
1 | languages := []string{"Go", "Python", "C"} |
或者使用内置函数 make 进行初始化,make 的函数定义如下:
1 | func make([]T, len, cap) []T |
第一个参数是 []T,T 即元素类型,第二个参数是长度 len,即初始化的切片拥有多少个元素,第三个参数是容量 cap,容量是可选参数,默认等于长度。使用内置函数 len 和 cap 可以得到切片的长度和容量
容量是当前切片已经预分配的内存能够容纳的元素个数,如果往切片中不断地增加新的元素。如果超过了当前切片的容量,就需要分配新的内存,并将当前切片所有的元素拷贝到新的内存块上。因此为了减少内存的拷贝次数,容量在比较小的时候,一般是以 2 的倍数扩大的,例如 2 4 8 16 …,当达到 2048 时,会采取新的策略,避免申请内存过大,导致浪费。Go 语言源代码 runtime/slice.go 中是这么实现的,不同版本可能有所差异:
1 | newcap := old.cap |
切片和数组很相似,按照下标进行索引。切片本质是一个数组片段的描述,包括了数组的指针,这个片段的长度和容量(不改变内存分配情况下的最大长度)。
1 | struct { |
切片操作并不复制切片指向的元素,创建一个新的切片会复用原来切片的底层数组,因此切片操作是非常高效的。下面的例子展示了这个过程:
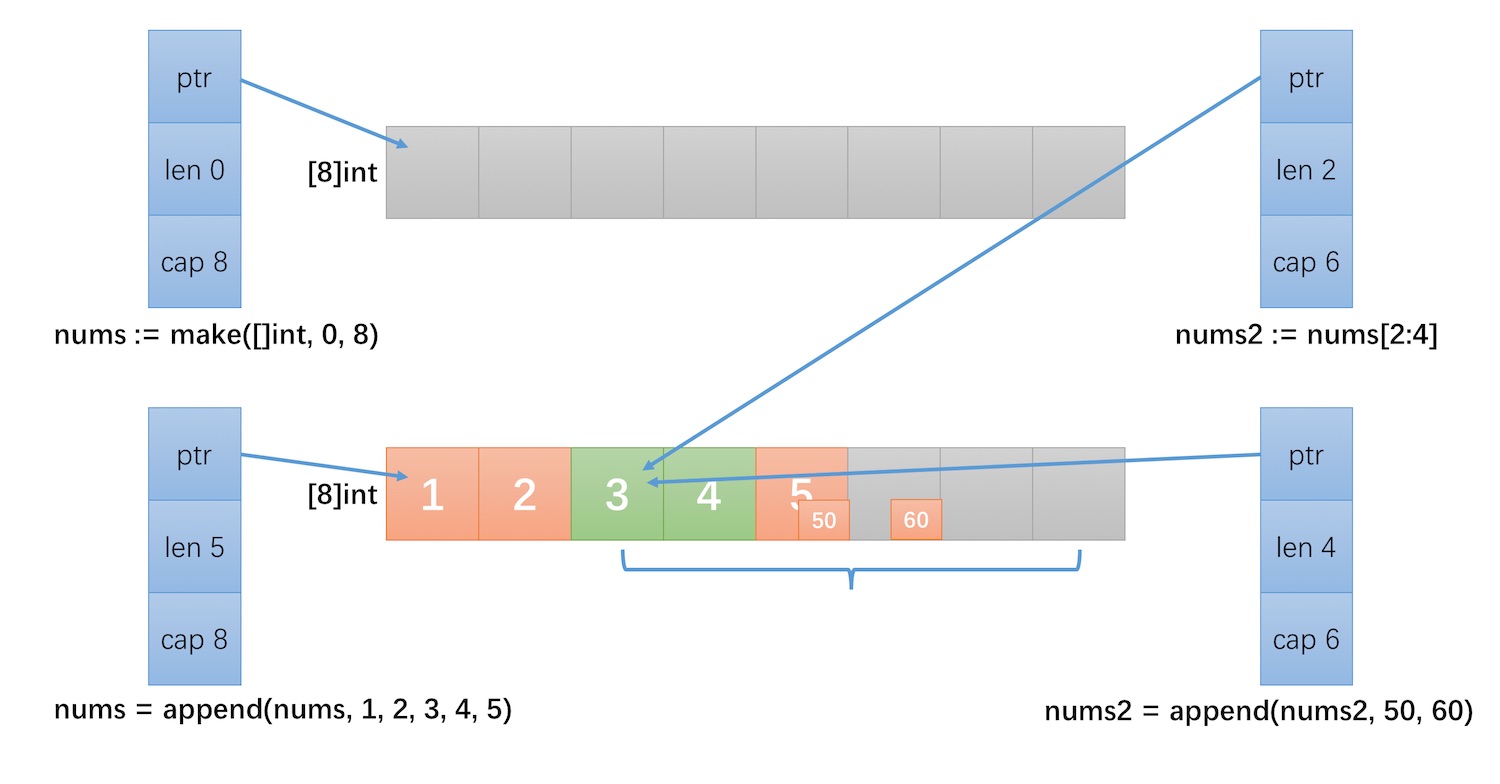
1 | nums := make([]int, 0, 8) |
- nums2 执行了一个切片操作
[2, 4),此时 nums 和 nums2 指向的是同一个数组 - nums2 增加 2 个元素 50 和 60 后,将底层数组下标 [4] 的值改为了 50,下标[5] 的值置为 60
- 因为 nums 和 nums2 指向的是同一个数组,因此 nums 被修改为 [1, 2, 3, 4, 50]
搞清楚切片的本质及其和数组的关系后,我们来看具体的性能优化点
提前为slice分配确定的内存
当我们确定一个 slice 的 capacity 时,直接使用 make 方法的第三个参数: make([]T, 0, len)
有时即使我们不能确切地知道一个 slice 的 capacity 时,如果这个 slice 的生命周期够短且在运行时不会持续增长,我们也可以给它分配一个足够大的 capacity,这样可以避免频繁的扩容带来的消耗
copy是一个好函数
当我们想合并两个 slice 时,我们一般会直接使用 append(s1, s2),但append的行为其实是不确定的,当s1的capacity不够大时,append会创建一个新的 slice s3,和s1, s2都不共享底层数组;而当s1的capacity足够大时,append会直接让新的 s3 和 s1 共享底层数组,见下面的例子:
1 | package main |
输出为:
1 | output |
这里由于共享了底层数组,所以 s1[0] 的值也改变了
这里可以使用 slice 切片的第三个参数避免这个不确定的行为,保证分配新的底层数组:
1 | package main |
输出为:
1 | output |
但这里我们可以用更高效的方法——copy,并且我们还可以写一个可以 merge 多个数组(append你做得到吗?!)的泛型版本 merge:
1 | func concatMultipleSlices[T any](slices [][]T) []T { |
避免不必要的的数组创建
首先我们要知道,在Golang中函数传参都是传值而不是传引用
但当参数为slice、map和chan时,其效果看上去像传引用,因为他们内部有指针或本身就是指针
它们都可以通过make内置函数创建,那么我们去追踪一下make函数的实现,看下其返回值,最终我们可以追踪到下面的源码:
1 | func makeslice(et *_type, len, cap int) slice { |
可以看到,make函数对于slice创建返回的是slice的结构体实例,对于map和chan的创建则返回的是对应的header指针,而slice结构体的定义如下:
1 | type `slice` struct { |
slice结构体里有一个指向底层数组array的指针,所以slice在作为函数参数传递进去的时候,虽然和map以及chan一样可以修改其中的值,但是内部slice若使用append之类的方法修改了大小,则这部分长度信息的变化不会反馈到外层slice中,甚至会因为底层数组扩容导致内外slice指向了不同的底层数组,进而后续的所有修改也将不会再影响到外部,使用的时候一定要小心;而map和chan因为本质上就是指针,故所有函数内的变动都会反馈到外面,除非在函数内部改变了这些指针指向的内存(这也是map和chan的copy的实现方法)
所以当我们传参处理 slice 时,如果我们不需要 append 或是改变它的长度,而仅仅需要处理更新其内含的元素,那么我们可以直接在原slice上操作,甚至可以不返回它
确保slice被正确地GC
在已有切片的基础上进行切片,不会创建新的底层数组。因为原来的底层数组没有发生变化,内存会一直占用不被 GC,直到没有变量引用该数组。因此很可能出现这么一种情况,原切片由大量的元素构成,但是我们在原切片的基础上切片,虽然只使用了很小一段,但底层数组在内存中仍然占据了大量空间,得不到释放。比较推荐的做法,使用 copy 替代 re-slice
1 | func lastNumsBySlice(origin []int) []int { |
上述两个函数的作用是一样的,取 origin 切片的最后 2 个元素。
- 第一个函数直接在原切片基础上进行切片
- 第二个函数创建了一个新的切片,将 origin 的最后两个元素拷贝到新切片上,然后返回新切片
我们可以写两个测试用例来比较这两种方式的性能差异:
在此之前呢,我们先实现 2 个辅助函数:
1 | func generateWithCap(n int) []int { |
generateWithCap用于随机生成 n 个 int 整数,64位机器上,一个 int 占 8 Byte,128 * 1024 个整数恰好占据 1 MB 的空间。printMem用于打印程序运行时占用的内存大小。
接下来分别为 lastNumsBySlice 和 lastNumsByCopy 实现测试用例:
1 | func testLastChars(t *testing.T, f func([]int) []int) { |
- 测试用例内容非常简单,随机生成一个大小为 1 MB 的切片( 128*1024 个 int 整型,恰好为 1 MB)。
- 分别调用
lastNumsBySlice和lastNumsByCopy取切片的最后两个元素。 - 最后然后打印程序所占用的内存。
运行结果如下:
1 | go test -run=^TestLastChars -v |
结果差异非常明显,lastNumsBySlice 耗费了 100.14 MB 内存,也就是说,申请的 100 个 1 MB 大小的内存没有被回收。因为切片虽然只使用了最后 2 个元素,但是因为与原来 1M 的切片引用了相同的底层数组,底层数组得不到释放,因此,最终 100 MB 的内存始终得不到释放。而 lastNumsByCopy 仅消耗了 3.14 MB 的内存。这是因为,通过 copy,指向了一个新的底层数组,当 origin 不再被引用后,内存会被垃圾回收(garbage collector, GC)。
如果我们在循环中,显示地调用 runtime.GC(),效果会更加地明显:
1 | func testLastChars(t *testing.T, f func([]int) []int) { |
lastNumsByCopy 内存占用直接下降到 0.15 MB。
1 | go test -run=^TestLastChars -v |
总结
对 Golang 的数组和切片,仅需牢记两点:
- slice 是基于底层数组的
- 数组的频繁扩容操作会消耗大量性能