如何为私有大语言模型快速沉淀高质量数据集
前言
在构建text-to-sql模型时,高质量的数据和有效的数据流程是必不可少的。目前市面上已经有许多优秀的开源大模型,如ChatLLaMa、Alpaca、Vicuna、以及Databricks-Dolly,Stable Diffution母公司发布的StableLM等
此外,还有一些训练框架可供选择,比如LMFlow和微软最近开源的DeepSpeed等
但即使开源的大模型和训练框架都越来越多,它们也都离不开高质量数据和生产高质量数据的流程,这也是一切模型构建的前提;这篇文章就来讲一下在私有项目中我是如何持续积累高质量数据集,并沉淀相关流程框架的
需要了解的词
Prompt Engineering
一种为生成式AI模型设计和提炼
prompt的方法论 / 框架,通常是规定 / 限制从模型中获得所需输出的框架,并持续的通过实验和分析来优化这些promptPrompt Engineering很重要,因为它可以显著影响NLP模型的性能,特别是对于微调任务。设计良好的prompt可以使模型生成更准确和相关的响应,而设计不当的提示可能会导致不准确或无用的输出,Prompt Engineering能够帮助我们进行LLM对接、构建和理解其功能,并提高其安全性Prompt Engineering的常见技术包括限制prompt的长度和结构、合并上下文和背景知识,以及使用各种类型的提示,如填空式prompt、多项选择或自由格式文本promptOpenAI API 代理
由于在国内ip直接调用OpenAI官方API可能会导致封号等问题,为了避免这些问题带来不必要的损失,我们通常还可以选择许多国内服务商提供的OpenAI API 代理服务,它们能以接近官方API的价格提供相同调用方式的代理服务(那些价格低于官方API价格的建议不要使用,往往是一些非独占token的服务,通过维护大量Free Granted账号实现,也并不稳定)
开源数据集
在开源社区中存在着许多文本到text-to-sql数据集,包括但不限于WikiSQL, SParC, Spider, HybridSQL, CoSQL等。这些数据集可以作为模型的训练集、验证集和测试集,并且其高质量的标注使得它们有资格评价模型性能的标准,这些开源数据集通常也维护了一份LeaderBoard来show出使用它们训练出的模型表现,如下是我收集的来自huggingface, paperswithcode, Github的一些优质的text-to-sql数据集:
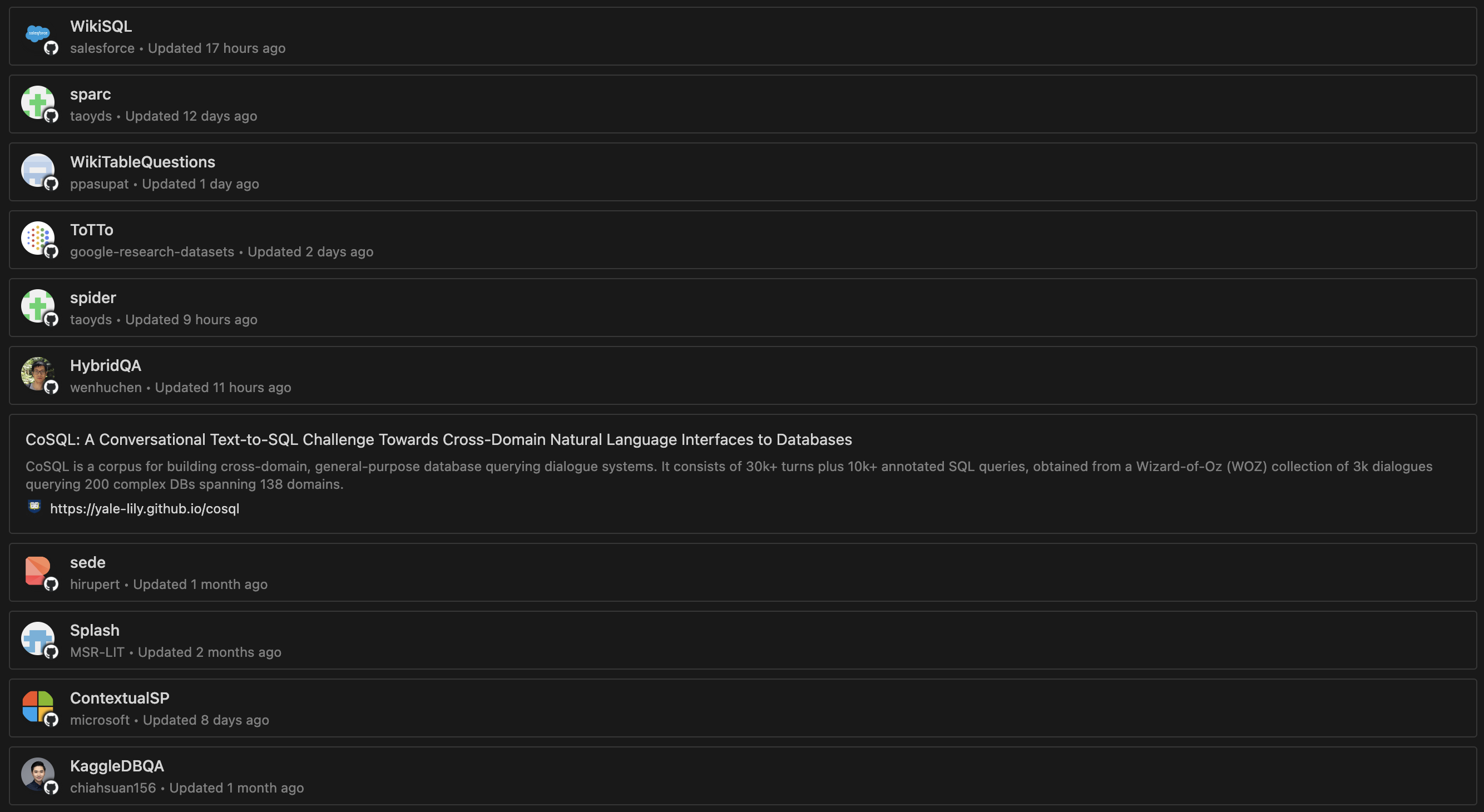
这些数据集经过一些格式处理和信息补充,即可直接作为我们模型的训练数据集;格式处理过程这里不做过多阐述,完成格式处理后,还需经过数据校验以及SQL分析,这些功能由下面介绍的Prompt-Collector提供
Prompt-Collector
除了上面提到过的方式——使用已有的开源数据集,我们还可以通过基于GPT-3.5这个已经“大成”的LLM chatbot生成自定义数据集。而为了大量的生产包括但不限于text-to-sql场景的高质量数据集,我们首先需要一套完整的数据集生产框架,囊括数据生成,生成后的数据分析,数据验证,以及生成结构化的Prompt等功能
这里我基于cobra提供的创建类git / go tools命令行工具的能力,实现了提供一整套数据集生成能力的命令行工具Prompt-Collector,以下是Prompt-Collector的架构图:
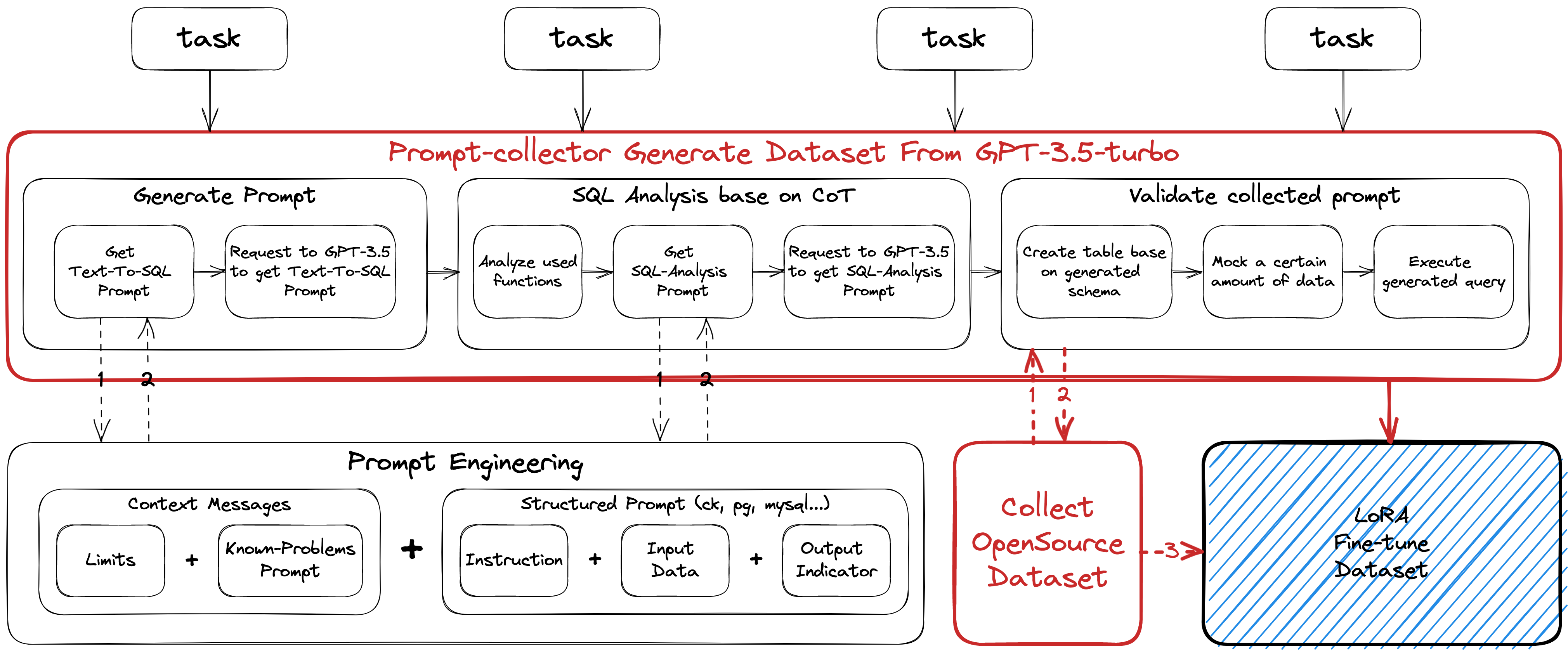
Prompt Engineering
首先我们来看看最基本但也是最重要的数据集生成,这里的数据集生成是指通过prompt让GPT-3.5模拟LLM instruction completion接口的输入和输出来生成数据集;在这个子步骤中我们需要使用到一些prompt engineering的技巧来设计生成数据的方式,这里我简单介绍一些prompt engineering的基础内容,详细内容我会在后续文章中展开阐述:
Temperature
我们可以在OpenAI的官方API文档中看到这个参数
简单来说,Temperature越低,结果就越具确定性,因为这样
LLM更倾向于可能更高的下一个token;而Temperature升高可能会导致更多的随机性(换句话说也可以是更多的创造性),这实际上是在增加其他可能token的权重在应用方面,我们可以对基于事实的
类QA任务使用较低的Temperature,以确保其返回确切的事实和简洁的回答;而对于诗歌创作或其他Idea型任务,我们则可以选择适当地增大Temperature(其值域为0到2)以获取更多创造性的输出我们当前获取数据集时设置为
0.3,能够比较稳定的输出标准格式的数据并且能够输出比较多样化的Schema和Query⚠️注意:一般来说只调整Temperature就够了,不需要和类似的另一个参数Top_p一起调整
zero-shot prompting / few-shot prompting
zero-shot prompting指的是
prompt中只包含直接的问题或是说明(没有任何希望它完成的任务的示例或演示)1
<Question>? / <Instruction>
相对应的,few-shot prompting指的是提供少量希望LLM输出的示例,如经典的QA格式:
1
2
3
4
5
6
7
8Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A: <Answer>
Q: <Question>?
A:更具体的,我们可以拆解一下我们的
prompt构成:- Instruction - 希望模型执行的特定任务或指令(如:“生成一份建表语句”,”将指定text翻译成中文“)
- Context - 可能涉及外部信息或其他上下文,帮助模型理解输入和输出的关系,以引导模型做出更好的响应(如QA示例)
- Input Data - 我们有兴趣找到答案的输入/具体问题(与Instruction对应,如:”使用该语句建的表至少包含3列“, ”Hello!“)
- Output Indicator - 指示输出的类型或格式(如邮件格式 / 指明字段的
JSON Format等)
基于以上构成,我们就可以具体描述大部分任务,并指示
LLM更有效地返回内容,当然,也不是所有问题都需要这完整的四部分,仅仅一条简短的Instruction也可以收获到高质量的response
基于上面提到过的prompt构建技巧和框架,最终我们就可以得出一个比较有效的prompt了,如以下是我在获取针对clickhouse数据源的text-to-sql数据集时初步使用的一个prompt:
1 | ## Instruction |
这个版本的prompt包含了Instruction, Input Data 以及 Output Indicator,在能够保证输出格式稳定为pure JSON的同时,也能比较好的覆盖到全部的clickhouse函数使用场景,且在后续的Validate中达到较高的留存率
当然,prompt构建是一个迭代过程,需要进行大量试验才能获得有效且稳定的结果,这并不是一蹴而就的;这份prompt在后续也被我拆解成了成更简单的子任务prompt,并针对其返回结果进行持续优化。在prompt构建的初期并不建议写大段的prompt,而是应该从简单的prompt开始,不断添加更多的元素和上下文,以获得更好的结果,其实很多简单的prompt也能收获很好的高质量response
而当我们有一个涉及许多不同子任务的大型任务时,我们可以试着把任务分解成更简单的子任务(分步骤 / 分问题),分别完成逐步的prompt构建,不断积累;在子任务都能获取到稳定的response后,再尝试合并;这就避免了在项目前期给prompt设计过程增加太多的复杂性
其余的一些prompt设计的技巧和注意事项我会在另一篇Prompt-Engineering的专题文章中介绍,这里不继续展开
Request OpenAI API
准备好生产text-to-sql dataset的prompt后,我们就需要真正地调用OpenAI API生产数据集了,这里我们使用go-openai管理OpenAI client以及调用API
首先初始化Client:
1 | client := openai.NewClient(token) |
client初始化完成后,设置好model, messages, maxToken以及temperature(上面介绍过的关键参数,这里设置为0.3),调用其CreateChatCompletion方法即可:
1 | // Create a new instance of the CompletionRequest struct |
成功拿到response后,即可直接从response.Choices[0].Message.Content获取到返回的内容,再进行进一步解析(同时我们还可以从resp.Usage.TotalTokens获取到该次请求消耗的token数)
在进行实际请求时,我们还需要处理以下两种异常情况:
429 Rate Limit
OpenAI的API都有请求频率限制(官方文档),尤其是Free Granted API Key的Rate Limit,目前为3次每分钟,见下图,RPM指每分钟请求限制,TPM指每分钟token限制),而我们的token池包含了部分免费token(压低总体成本以及填充其它key的Rate Limit);基于这种现状我就需要构建一个限制对应频率的OpenAI client池来访问OpenAI API
504 Gateway Timeout
我们的token池中还包括了部分
OpenAI代理服务token,虽然代理服务解决了大陆地区访问OpenAI API导致封号的问题,但由于代理服务器的稳定性等问题,也会出现偶现的504,这时可以进行简单的重试,也可以在重试一定次数无果后更换为非代理client进行访问
完成了异常请求的处理后,我们就可以稳定的获取数据了
这里我们前期选择使用jsonl格式直接存储数据(一行是一份数据),方便生成数据时并发写入文件,以及在超时控制 / 异常处理时可以直接中断任务上传结果数据集文件到构件 / 仓库等
至此我们成功从GPT-3.5-turbo拿到了想要的text-to-sql dataset,但为了保证生成数据的质量,我们还需要对数据进行校验
数据校验
获得GPT-3.5生成的数据之后,无疑我们仍然需要进行严格的数据校验
在text-to-sql模型中,常见的数据错误包括但不限于问题理解歧义、缺失信息、语言表述不准确、甚至更严重的SQL无法执行等问题。为了避免这些问题,在构建文本到SQL数据集时,应该尽可能地消除这些数据错误,以确保训练出来的模型表现最佳
而在这些问题中,我们可以通过自动化校验消除SQL无法执行的错误
一份 AI-SQL 训练数据结构如下:
1 | type ( |
数据校验分为以下几个步骤:
连接到
Datasource对应的数据库根据
Schema建表这一步中,需要将Schema和Query中的表名加上uuid以避免在校验过程中遇到重名表(为了保证
thread-safe)执行一次全字段的空查询以获取所有列信息,通过
ColumnType, 反射等获取到对应Golang基础类型的零值使用gofakeit库mock对应Golang基础类型的值,构建SQL后执行插入对应表;这里需要注意的是,在步骤3中获取到的「对应Golang基础类型」可能并不能在mock后再次插入数据库(由于数据库列类型和golang类型并不是1:1的关系),所以我们需要针对诸如date, smallInt, id, jsonp等类型编写mock逻辑1
SELECT * FROM <table_name> LIMIT 0

并且部分类型需要限制值域范围,如time和smallInt等,以精确适配数据库类型的值域范围
执行
Query
2, 3, 4, 5步骤均可能出现错误,3中的错误可忽略,其它步骤全部执行通过则确认该数据校验通过,同时收集返回结果以便做后续的面板展示
SQL分析
除了针对问题和schema获取到执行的Query,在这样的问题背景下,我们还希望了解得到这样的Query的具体思路,以支持ABP调优中的【学习复杂函数问题】这一项,代替原来的基于llama_index构建复杂函数文档的方案
首先我们可以直接从Query中解析出全部用到的函数(在完成上述数据校验的步骤5校验后),并根据提前收集好的各数据源函数集合找到其对应功能(这样在利于LLM推理分析的同时,生成的数据也将在训练时把各数据源的函数信息喂给LLM,一举两得),以此为基础构建prompt:
1 | ## Instruction |
值得注意的是,这里我使用了CoT(Chain-of-Thought)的prompt构建技巧,即Input Data部分的最后一句话:
Solve by breaking the problem into steps. First, Analyze the question; second, understand the schema and bind the question; third, write the Query, and then explain why we used the functions
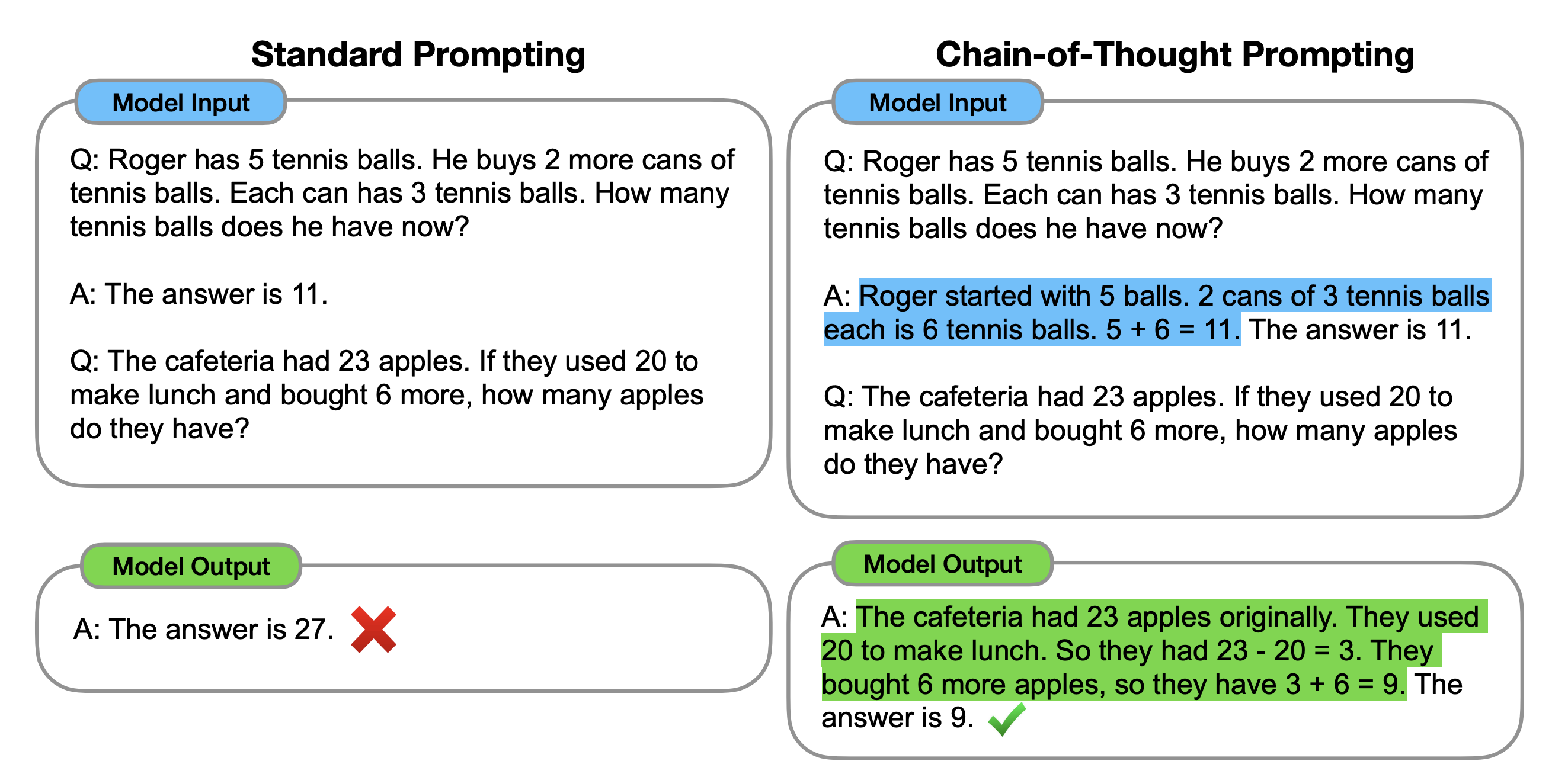
对于目前的LLM来说,如今最困难的任务之一可能是需要某种形式的推理;而使用CoT提示就可以通过中间推理步骤,让LLM实现复杂的推理能力,有关CoT的具体内容我会在另一篇Prompt-Engineering的专题文章中介绍
最终该prompt可以实现这样的效果:
1 | ## Step 1: Analyze the Question |
有了这样的CoT链prompt,不仅能够让LLM明白各个函数的具体功能,也能为LLM提供text-to-sql问题的推导思路,以实现一些复杂查询的推导;这一部分的分析也可以考虑移到数据校验之前,与数据生成的部分做一个整合,这样补充Analysis信息后的数据集也经过了验证,最终模型在问题理解能力和SQL推理能力都比未添加Analysis信息前要好得多
CI工程化
实现了上述的基于GPT-3.5生成数据集以及数据校验后,我们可以通过使用CI/CD pipeline将数据集的构建和自动化数据校验过程结合起来,以确保我们能够快速、可靠地构建数据集并过滤掉低质量数据,同时也为后续上线使用中的反馈流程打好基础,确保我们的数据集始终处于最佳状态,并且可以随时部署到我们的模型中
基于prompt-collector提供的比较友好的命令行调用方式,我们可以使用下述命令直接生成和校验AI-SQL的数据集:
1 | # 可以分两步 |
随后完成配套的流水线搭建,实现定时的数据集生成和数据集校验(这里将-c设置到比较高的值并将--timeout设置为与流水线触发周期间隔相同的时间,以实现24小时满载运行,并且timeout参数保证了在遇到异常情况时能及时终止并将已生成的数据及时上传和持久化)
当前开启8并发(--concurrent 8)的情况下,生产数据的速度可以达到6400条 / h,单次请求消耗如下(生产5条数据),计算可得生产每条数据消耗约为0.0004美元
| 模型 | 问题消耗 Tokens | 回答消耗 Tokens | 总消耗 Tokens | 费用(美元) |
|---|---|---|---|---|
| gpt-3.5-turbo-0301 | 480 | 580 | 1060 | 0.00212 |
初期可以直接在完成生成和校验后将新数据写回仓库,直接开始运行训练任务

后期可以持续的写入数据库或是其它存储介质,方便做后续的处理和使用
总结
我们可以选择直接使用开源数据集,如WikiSQL、SParC、HybridSQL、CoSQL等的数据集,也可以使用基于GPT-3.5生成的数据集(在一些开源数据集匮乏的场景下吗,如clickhouse复杂查询的text-to-sql数据),在基于GPT-3.5生成数据集时也就需要使用prompt engineering的技巧来提高生成数据集的效率和质量,并不断迭代更新结构化的prompt,以支持和实现CoT链等特性
在获取数据后,我们还需要进行严格的数据校验,以确保我们构建的text-to-sql数据集是高质量的;除此之外,我们还需要进行SQL分析,以了解SQL的具体思路,将思路也融合进训练数据集中,提升其问题理解能力和SQL推理能力,以支持其构建更加复杂的查询
最后,我们可以使用CI实现自动化构建数据集,以持续支持我们的模型训练及反馈流程等,最终实现全自动炼丹的一整套框架