Whosbug项目日志2
背景信息
团队规模
whosbug经手了多个团队的近20人,历史团队中:大家分别负责插件和数据流转的设计实现和优化、责任归属算法的设计实现与优化、antlr语法AST分析的多语言适配实现以及项目协同的管理;当前主要由kevineluo和kevinmatthe负责维护以及开源相关的规划,同时开源团队也有其它8位同学一起协作共建
业务内容
提供DevOps流程中的CI流水线插件,为线上项目提供发生错误时实时归属责任人的能力
项目诉求
关键痛点
在很多大型项目中,一个重要缺陷往往会在不同的人手中流转很多次,这会导致很多不必要的时间成本和人力成本,甚至在一些情况下会引发新的问题(如修复人在对模块不熟悉的情况下进行了不恰当的bugfix)
项目目标
whosbug致力于解决责任人归属这一问题的一个微服务,精确的定位到每一个crash / bug的责任人,缩短缺陷修复流程;同时也能在语法树这一层级为项目提供部分统计信息
项目现状
初版尝试在自动化测试产品(NewMonkey)、移动性能监控(QAPM)场景中接入了whosbug;近期也进行了一些更新,解决了下面提到的一些问题,不久后将会在内网发布,同时我们也将维护一个开源版本,为更多的人提供whosbug的服务
关键挑战&解决措施
1. 大型仓库的冷启动问题
大型仓库首次接入whosbug流水线插件进行解析时,会造成内存装载量过大,容易导致流水线机器OOM

解决措施:
- 减少单次内存装载数据量,处理完毕的数据及时抛弃(以及必要的手动
GC) - 优化数据流动的过程,减小重复的内存开销,提高数据结构的复用能力
2. 数据处理的效率低下问题
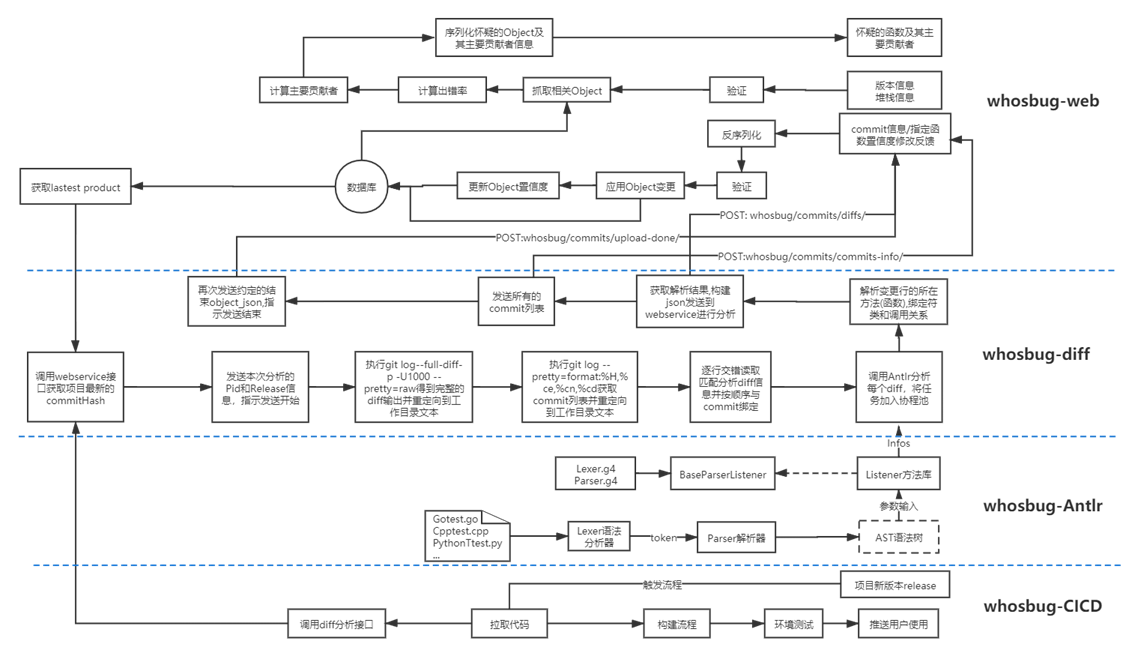
单线进行的数据接入对diff内容的解析利用率有限,每次仅能处理单个diff或每次只能处理单个commit,无法有效的利用空闲的性能,效率低下
解决措施:
引入协程池,将每一个未处理的
diff内容作为task送入协程池队列,并发处理多次的数据(充分利用高IO并发下的空闲吞吐量)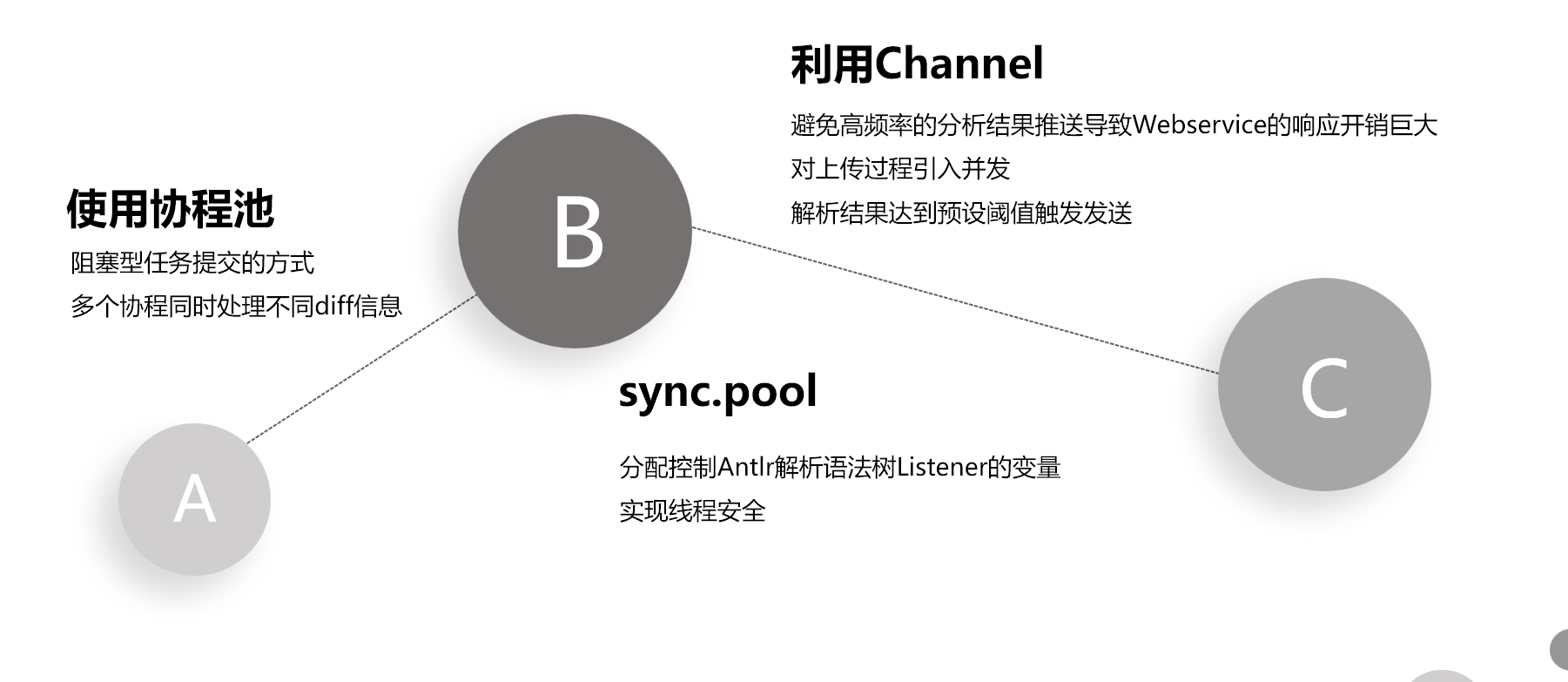
动态调整并发数目,避免并发数目过多导致的性能下降 / 程序崩溃
使用
pprof等工具对程序工作过程中的CPU时间和内存占用进行记录分析,提供内存优化的思路和方向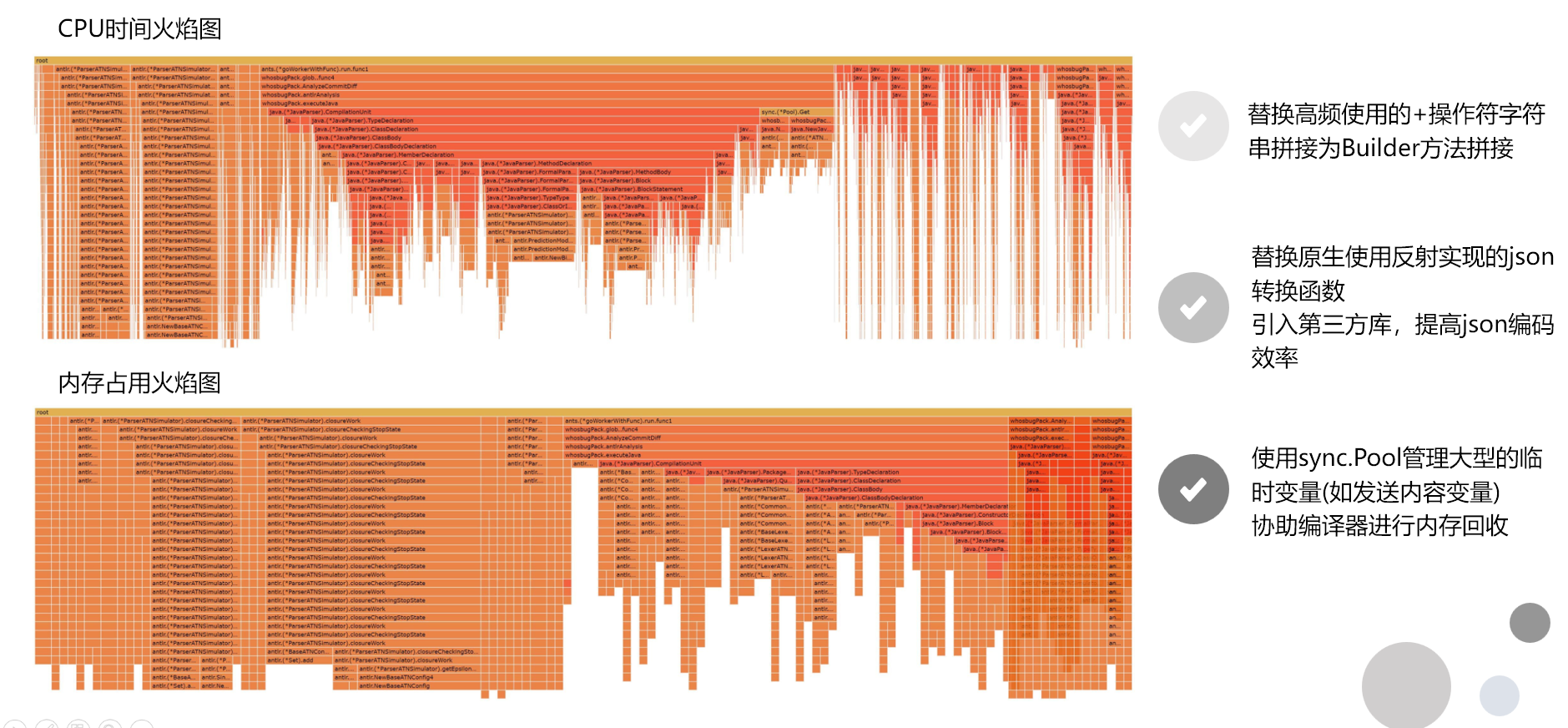
3. 多语言支持的适配性
原版使用ctags作为AST解析的工具时,对不同语言的支持适配很难复用,需要针对每一种语言重新适配,几乎需要为每个语言设计不同的接口,基本上不具有泛用性

解决措施:
- 使用
Antlr作为AST解析的工具,使用统一的Go-Antlr Runtime - 定义广义的语法解析结构的接口,覆盖所有适配的语言,统一接口调用便于开发维护
4. Antlr-Go线程不安全
Antlr的Go Runtime原生并不是线程安全的,而这一点在Antlr的doc里面没有明确指出,亦没有提供实现线程安全的方法示例,在实现语法解析的并发执行的过程中遇到了阻力
5. 责任人归属算法的优化
whosbug中最重要的莫过于责任人归属算法了,算法的优劣决定了整个微服务的效果;初版发布后我们进行了一系列的测试,发现了老算法在一些场景下的局限性(如对没有第三方库调用的处理、多语言下的泛用性不足等问题)
于是在参考了部分论文后,我们结合实际落地场景设计了新的责任人归属算法 —— Keyman
解决措施:
- 使用
sync.Pool互斥管理语法解析树的Listener实例,实现其线程安全 - 为
Listener的接口增加实现实例内的共享变量,帮助AST分析获得完整的语法解析树