Whosbug项目日志3
前言
今年是whosbug持续推进的第三个年头,经过2022届mini项目同学们的努力,whosbug在CI插件/webservice性能、责任人归属算法等方面取得了长足的进展,同时也积极推动了对whosbug可观测性监控系统、文档和系统测试的建设
CI插件优化
老版本的CI插件在对大型项目进行静态语法解析时仍有耗时过长的情况,很大一部分的耗时用在了git diff解析,针对这一性能瓶颈进行了优化
优化前

优化后

系统测试
whosbug的系统测试需要大量的测试用例,且测试用例主要来源于 github 大型开源项目的 issue,需要找那些提供堆栈,且合入修复的 issue(合入修复者作为 target_owner),在优化工作进行时我们也持续的在收集测试用例
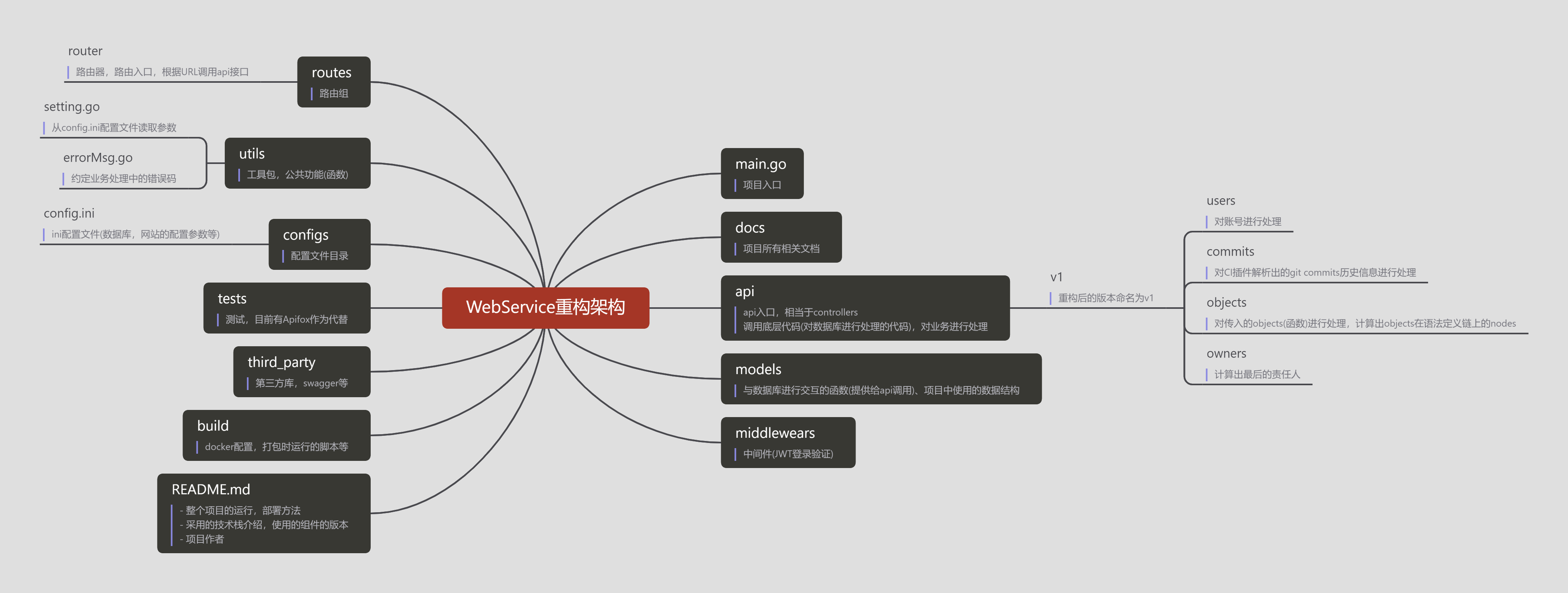
web service重构
从技术栈一致性出发,基于 Golang gin 框架重构了 whosbug web-service,保证 web-service 的性能,同时完善了相关文档及接口测试用例
责任人归属算法优化
当前的责任人归属算法有两个版本,一个是基于项目语法树的完整版本,一个是基于定义链的版本(在无完整语法树支持的语言中使用);我们结合语法解析插件现有能力和其它辅助信息对定义链算法进行了一定的优化,当前基于定义链的责任人归属算法如下:
主要思路
- 首先计算崩溃堆栈中每个函数的置信度
- 再计算每个函数对本次错误的贡献程度
- 最后计算责任人权重,最终返回一个主要责任人
- 可以根据需要返回可能出错的函数集及其对应的责任人,灵活选择即可
函数的全局唯一标识符
- 为了定位函数的位置,我们需要赋予每个函数一个全局的唯一标识符,这样即便是C++的重载函数也可以区分
- 路径.类域.函数域(参数域)
1 | packageA.packageB.classA.classB.funcA(paramA paramB).funcB(paramC paramD) |
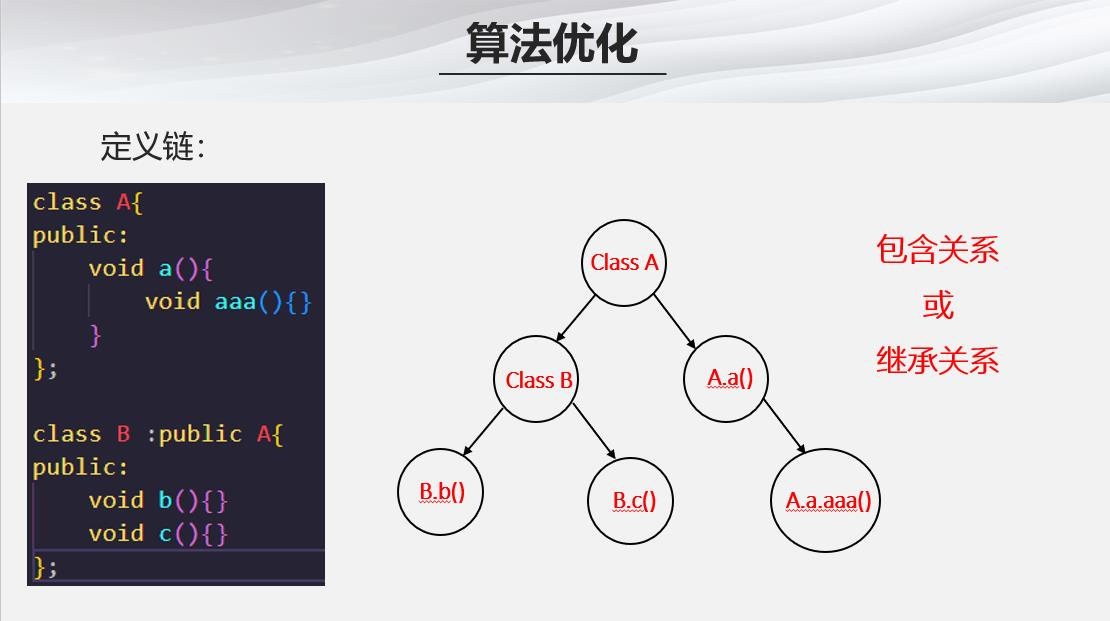
定义链
- 定义链即包含关系或者继承关系,这里展示一个简单的例子方便理解

置信度
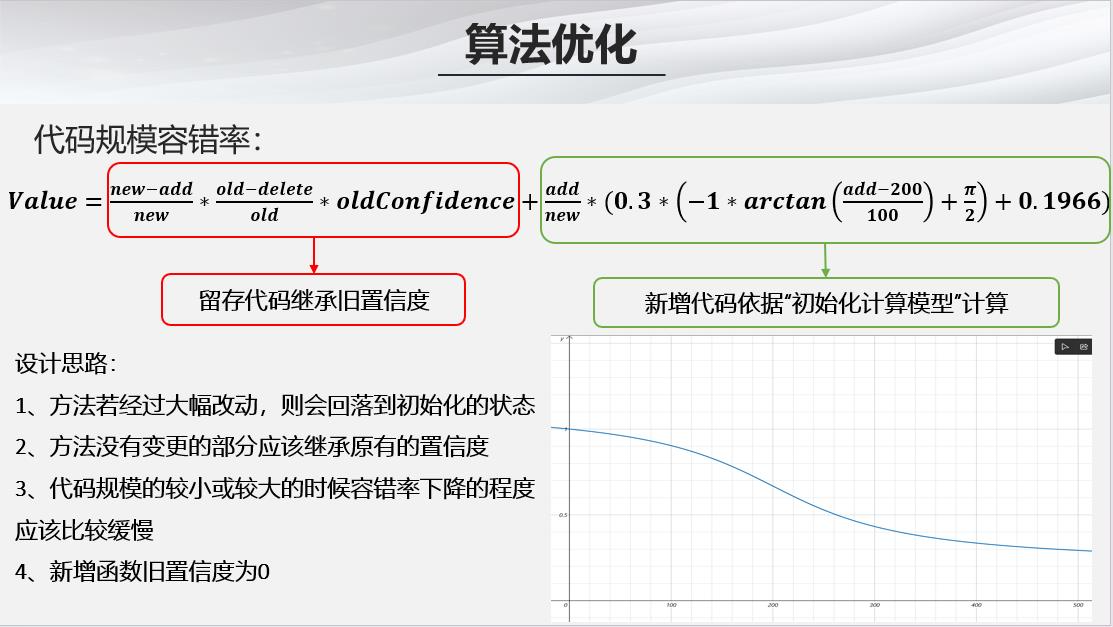
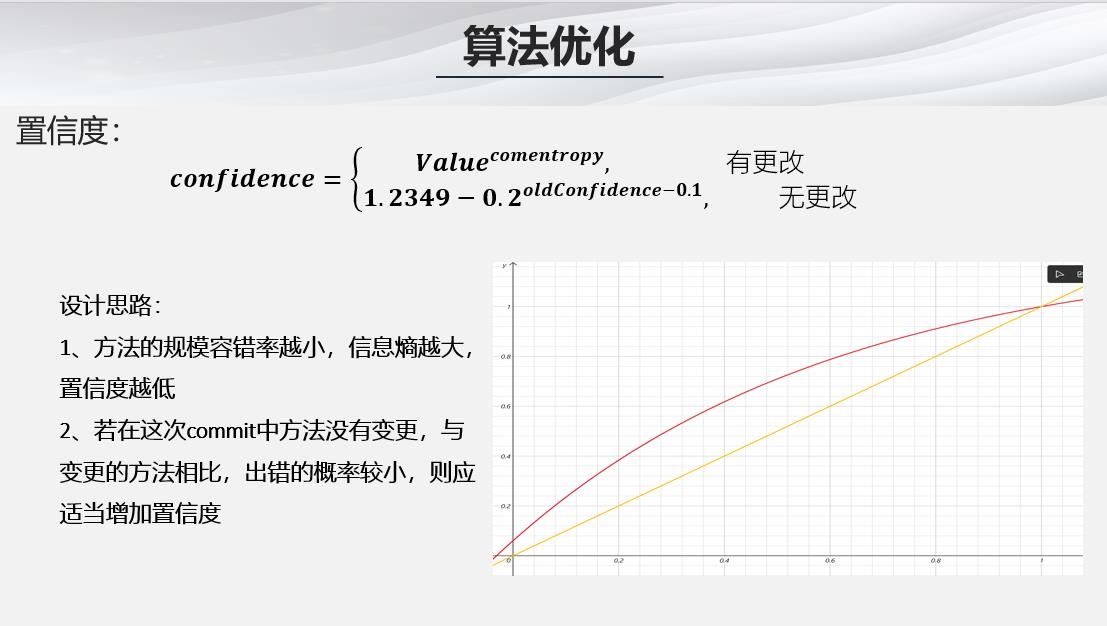
- 在计算函数的置信度之前,我们首先要根据代码规模计算函数的规模容错率,往往函数的规模越大,那么出错的概率越高
- 其次,我们还需要评估函数的信息熵,也就是函数的逻辑复杂度,如果在函数内部定义的“子函数”越多、深度越深,可以认为函数的逻辑复杂度越多,理解起来越困难,那么自然出错的概率也就高
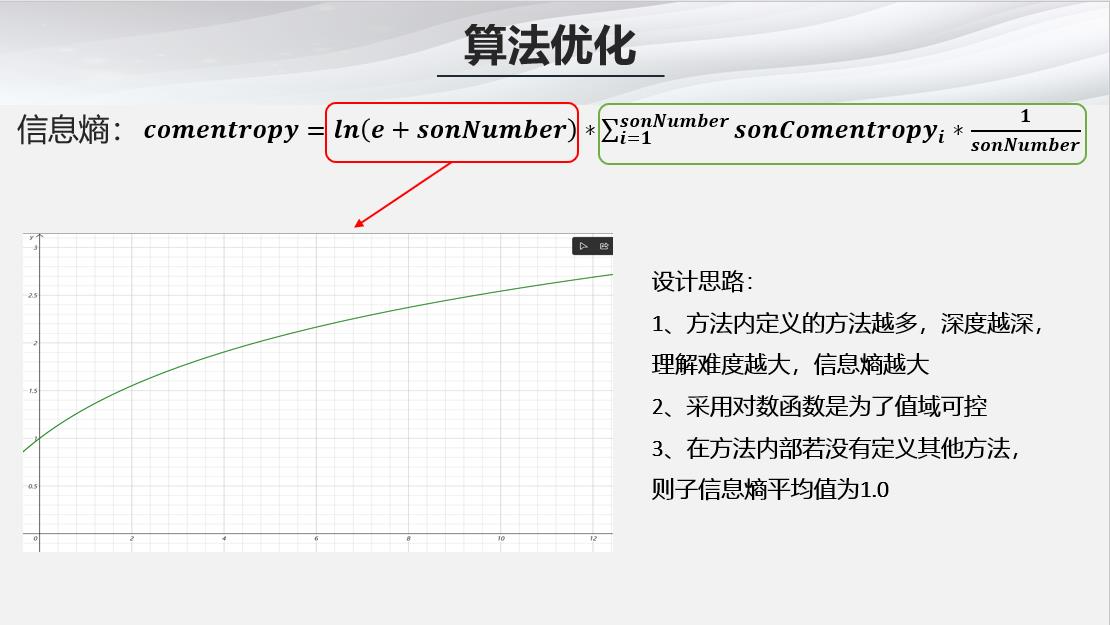
- 有了函数的规模容错率以及信息熵,我们就可以计算函数的置信度,如果在本次commit中该函数发生变更则采用上方公式重新计算,如果没有发生变更则采用下方的公式适当增加置信度



错误贡献度
- 虽然有了函数的置信度,但是并不能直接的判断是否该函数导致本次错误的发生,所以我们还需要根据报错堆栈的信息来计算每个函数对本次错误的贡献程度
- 导致错误的函数出现在报错堆栈中的频率更高
- 导致错误的函数与直接错误函数(栈顶)的距离越近


责任人权重
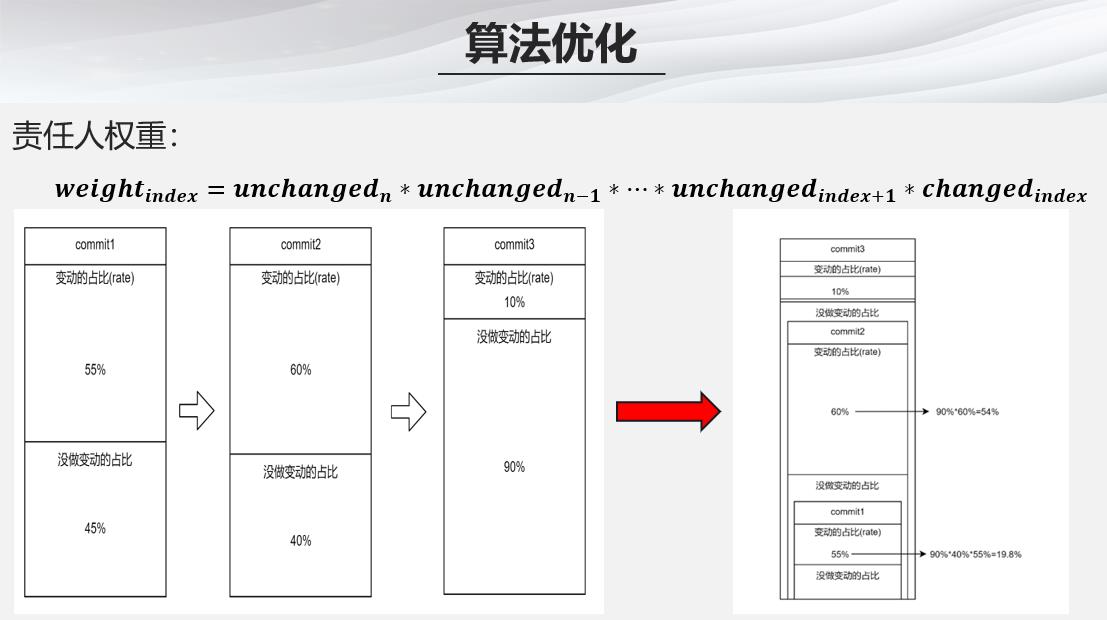
- 对于每个函数,我们可以根据历史修改记录来计算每个责任人的权重
- 一般来说,错误往往由于近期的commit中的函数变更导致的,因此越近的commit的作者的权重会越高
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Kevinello!
相关推荐




评论
UtterancesTwikoo