Golang panic&recover 详解
前言 近期在编写并发 goroutine 以及超时控制时,出现了意料之外的没有 handle 住的 panic ,导致程序直接退出 具体场景大致如下: 1234567891011121314151617181920212223242526272829303132333435363738394041424344func main() { defer myRecover() ctx, canceller := context.WithTimeout(context.Background(), 1*time.Minute) defer canceller() startTime := time.Now() done := make(chan struct{}, 1) // do task go func() { defer close(done) panic("some panic") done <- struct{}{} }() select { cas ...

一次磁盘清理导致的docker启动失败
前言 近日想要在我的云服务器上安装graphviz时,发现我的根目录盘满了(直到现在也是快满的状态,服务商说根目录无法扩容🤔🤔🤔) 于是通过逐层执行du -h --max-depth=1,我着手删除了一些比较占磁盘空间的文件 并且顺手扩容了这台云主机的磁盘,reboot了一下, 然后我发现我的docker没有正常地自动启动,尝试手动启动也失败了 需要了解的词 systemctl 用于控制systemd服务,类比k8s中的kubectl 软链接(symbolic link) 一个文件在某一路径下的同步链接(不重复占用磁盘空间,且实时同步) Failed to get D-Bus connection 首先遇到的报错就是这个了 12# systemctl start dockerFailed to get D-Bus connection: Operation not permitted 不多废话直接Google,但按大家描述的场景都是在docker容器内使用systemctl时出现的这种情况 具体原因是systemd是需要特权(CAP_SYS_ADMIN)去 ...
记一次国密落地的经历
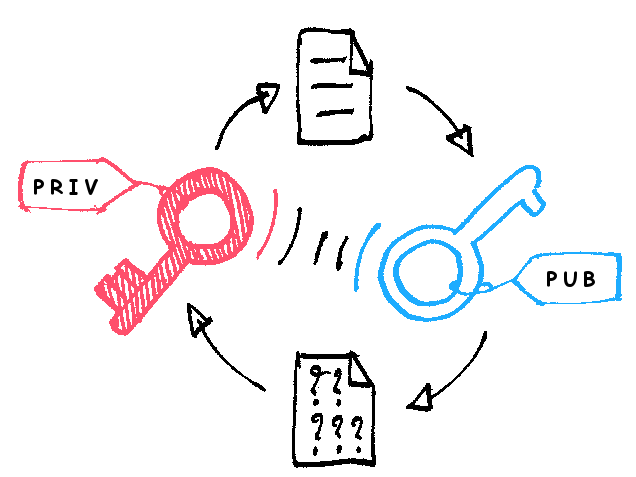
前言 在一般意义上的后台服务中,身份认证可以保证数据源没有问题,完整性校验可以保证数据没有经过窃听者的篡改,但我们还要防止窃听者知道数据的内容,这就还需要加解密来帮助我们守住最后一道围墙 而在私有云交付的环境中,我们无法用现有的公司平台加解密服务,并且按照国家、金融行业等要求,需要用国密算法实现的加解密方案 国密存在哪些问题 使用不便 最大问题是使用不便。这是由于国密不在IETF国际标准中,不同于ECDSA、ECDH、RSA等国际算法,系统中往往包含相关标准加解密方式,业务数据包通过HTTPS传输时完全不用考虑如何交换公钥,如何加解密数据。 因此现阶段使用国密必须在业务层手动进行数据加解密,相当于对数据进行一步额外的操作。 无最佳实践 确定业务层进行加解密后,应该使用哪一种国密实现、该如何进行加解密是另一个难点,且暂不存在一个最优解。国密的实现方案很多,包括TencentSM、GmSSL和KMS服务器,这也需要进一步的调研和测试来决定最终方案。 国密落地过程 国密落地分为调研、制定、实现与测试四个阶段。 调研阶段主要目的有两个: 找到性能高效、使用便捷并且有足够保障(维护活跃 ...

Distributed Tracing in Grafana -- Jaeger & Tempo
前言 在近几个月对某产品后台微服务的SLI建设过程中,逐渐意识到这类监控的最佳方式还是通过jaeger/opentracing这类链式tracing才能以最佳的监控数据结构提供全链路的数据监控 并且最近也看到了Tempo — 来自Grafana Lab的tracing backend,可以更好的处理大数据量的tracing以及更好地兼容在Grafana上的展示 于是写一篇文章来小小整理一下Jaeger和Tempo的内容 需要了解的词 tracing 追踪数据流的工具,下面会详细介绍 Grafana 基于Golang实现的完整可视化面板平台,同时也提供告警等功能 OpenTracing 由Tracing通用API规范、框架和库组成,可以在任何应用程序中支持Distributed Tracing Tracing是什么 尽管我们十分熟悉我们编写的系统,但在线上环境中,它对于我们来说依旧是黑盒;可能你会说我们有丰富的日志,但当系统日渐庞大,业务逻辑逐渐繁杂之后,再丰富的日志对于我们的运维排查来说也是杯水车薪,并且日志采集,日志埋点,和日志存储都带来不小的成本,复杂的日志反 ...
Run minecraft on mac pro m1
Run minecraft on mac pro m1 前言 由于MC自带的必要动态链接库LWJGL的架构是X86,不兼容mac pro m1处理器的arm64架构,原生的MC是无法在m1上启动的;同时由于Apple强推了Metal API,在部分mod / 光影 / 材质包上会有损失部分Feature的情况 经典放送: 基本设置 见arm64 minecraft wrapper 完成配置后可正常启动Minecraft mod支持情况 部分图形渲染相关mod会出现无法渲染文字 / 图像的情况 光影支持情况 m1下仅支持部分光影(部分光影会因为Metal API产生Error) 欣赏经典: 经过测试已支持的光影: https://github.com/MoustacheOff/AppleSilicon-Minecraft-Shaders 推荐使用 注意下载v1.20版本的 Slidur's Shaders,高版本的在m1上有性能问题

小刮刮Scrapy
前言 从大二开始接触python,到现在已经是第三个年头了;随着入职腾讯,进入云原生行业后,python已经不再是我的主要开发语言,我转而收养了golang小地鼠成为了一名gopher 但python依然是我的工具人好伙伴(日常生活中一旦有自动化的念头也会直接想到python),并且作为数据工作者,对于python的数据处理能力还是挺依赖的,golang的生态也没有好到能面面俱到 鄙人大二时课设写过一个小小的b站爬虫(基于bs4, re和selenium等简单写的),最后也只是草草爬了几十万的用户数据以及几百万的视频数据,做了做没有什么意义的词频分析,而scrapy作为我一定会忘记的爬虫必会知识,还是有必要写一篇小笔记record一下的 需要了解的词 网络爬虫:泛指获取网页信息,提取有用信息的行为 selenium: web自动化测试工具集,但在爬虫工程中也经常使用,模拟人的点击操作驱动浏览器来获取网页信息 Scrapy是什么 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。其最初是为了 页 ...

面试官初体验
前言 近期作为后台开发面试官整理的一些简单面试题(仅供参考仅供参考仅供参考 基础题 Golang Golang中函数调用是传值还是传引用 golang中所有函数参数传递都是传值,slice、map和chan看上去像传引用只是因为他们内部有指针或本身就是指针而已;slice结构体里有一个指向底层数组array的指针,所以slice在作为函数参数传递进去的时候,虽然和map以及chan一样可以修改其中的值,但是内部slice若使用append之类的方法修改了大小,则这部分长度信息的变化不会反馈到外层slice中,甚至会因为底层数组扩容(cap扩充)导致内外slice指向了不同的底层数组;而map和chan因为本质上就是指针,故所有函数内的变动都会反馈到外面,除非在函数内部改变了这些指针指向的内存(这也是map和chan的copy的实现方法) Golang中make和new的区别? make 只能用来分配及初始化类型为 slice、map、chan的数据,new可以分配任意类型的数据 new 分配返回的是指针,即类型 *Type。make 返回引用,即 Type new 分配 ...

Whosbug项目日志2
背景信息 团队规模 whosbug经手了多个团队的近20人,历史团队中:大家分别负责插件和数据流转的设计实现和优化、责任归属算法的设计实现与优化、antlr语法AST分析的多语言适配实现以及项目协同的管理;当前主要由kevineluo和kevinmatthe负责维护以及开源相关的规划,同时开源团队也有其它8位同学一起协作共建 业务内容 提供DevOps流程中的CI流水线插件,为线上项目提供发生错误时实时归属责任人的能力 项目诉求 关键痛点 在很多大型项目中,一个重要缺陷往往会在不同的人手中流转很多次,这会导致很多不必要的时间成本和人力成本,甚至在一些情况下会引发新的问题(如修复人在对模块不熟悉的情况下进行了不恰当的bugfix) 项目目标 whosbug致力于解决责任人归属这一问题的一个微服务,精确的定位到每一个crash / bug的责任人,缩短缺陷修复流程;同时也能在语法树这一层级为项目提供部分统计信息 项目现状 初版尝试在自动化测试产品(NewMonkey)、移动性能监控(QAPM)场景中接入了whosbug;近期也进行了一些更新,解决了下面提到的一些问题,不久后 ...

Keyman算法设计哲学
前言 whosbug项目中,最重要的无非是两个部分: 对接入项目的AST静态语法解析 责任人归属算法 whosbug初版发布后我们进行了一系列的测试,发现了老算法在一些场景下的局限性(如对没有第三方库调用的处理、多语言下的泛用性不足等问题) 于是在参考了部分论文后,我们结合实际落地场景设计了新的责任人归属算法 —— Keyman,本文我们就详细介绍下算法设计 主要设计思想 函数唯一标识 为了清晰一个函数在语法树中的精确位置,首先我们需要每个函数的唯一标识,这里我们的标识为: 并且包 / 类也视作一个函数,将包/类内的代码非函数内代码归入这个包 / 类的函数 获取可能和这次错误相关的函数 Init: 获取预设的迭代次数NUMBER_OF_ITERATION,新建相关方法集methods,以错误堆栈中涉及的所有方法为初值 不断地从methods内的每个函数/方法找到与其相连且未在methods内的方法,加入methods中,也同时得到该方法与直接错误方法的距离。如此全面进行NUMBER_OF_ITERATION次 1234567891011NUMBER_OF_ ...

TraceSim算法深入浅出
前言 现有研究使用的stack trace距离度量主要有以下两种: information retrieval techniques(基于信息检索技术) string matching methods(基于字符串匹配技术) Rebucket就是string matching methods的一种,这篇论文主要提出了TraceSim这一结合了两种方法的堆栈相似度度量方法 需要了解的词 Levenshtein Distance Calculation: 基于string matching methods的一种堆栈间距离的度量算法(本文中的Levenshtein Distance Calculation是其改进版本,下面会展开讲) TF-IDF: 基于information retrieval techniques的一种堆栈间距离的度量算法,其中TF代表单帧的重要程度,IDF代表单帧的罕见程度 TraceSim a novel approach to this problem which combines TF-IDF, Levenshtein distance, and m ...